AssertJ Core: Scalability
Over the past few weeks, we have been exploring the product vision, the architecture, and the quality of AssertJ Core. For this final essay, we will be exploring the scalability of this Java assertion library. The dimension we focus on is processing time and we examine this using an experiment directed at the low code health spots of the library.
AssertJ Core is a testing library, focused on providing tailored assertions to specific JDK types. This means that it will be used in test suites and by extension in CI/CD pipelines. In this scenario, processing time is very relevant, since many providers offer subscription plans based on CI/CD minutes per month (e.g. GitLab). This is also why we focus on running experiments on passing assertions, since most developers only use the pipelines once they know the tests are passing. We have used two experiments for gaining insight into the processing time of AssertJ.
Firstly, we used the results of an experiment focusing on the energy consumption of AssertJ in comparison to JUnit1. This experiment takes an existing JUnit test suite from the Guava library and compares it to an equivalent test suite with assertions from AssertJ Core. One of the investigated parameters was the total elapsed time, comparing which of the two is faster. This is relevant to determine whether the clarity of AssertJ comes with an acceptable increase in processing time. It is evaluated by comparing it to using the native assertions of the testing framework within which it operates.
Secondly, we devised and ran an experiment to measure the scalability of the assertions within the library with respect to processing time. It executes chosen assertions with increasing input sizes and watches for unexpected trends. This is relevant because AssertJ Core needs to properly scale when developers use it to perform scalability tests on their own systems. Therefore, this experiment focuses on comparing the runtime across assertions executed with various input sizes. We explain the experimental setup in the following section.
Experimental Setup
The goal of this experiment is to test the assertions with inputs of different sizes and then measure the time it took to run the assertion. To achieve this, we set up the following Experiment class (which can be found in its entirety in the experiment’s public repository):
public abstract class Experiment {
private final DataProvider provider;
private final AssertionRunner runner;
private final List<Long> results;
public Experiment(DataProvider provider, AssertionRunner runner) {...}
public void run(int size, int numOfSamples, long timeLimit) {...}
public void printOverview() {...}
public void writeResults(PrintWriter writer) {...}
public void writeResults(File file) throws IOException {...}
public void writeResults(String path) throws IOException {... }
@FunctionalInterface
public interface DataProvider {
Object[] generate(int size);
}
@FunctionalInterface
public interface AssertionRunner {
void run(Object[] data);
}
}
This class represents a single experiment which can be run a numOfSamples number of times. Each Experiment needs to implement its own runner as well as its own data provider. As an example, we present the experiment for the containsExactly assertion of the Map type. This experiment generates random strings as keys and values and adds them to both the actual map as well as the array of expected entries. The runner then executes the assertion and checks that the map contains exactly the entries in the same order. The code can be found below:
public class ContainsExactly extends Experiment {
static Experiment.DataProvider provider = (size) -> {
// create the "actual" map
Map<String, String> actual = new LinkedHashMap<>();
// create the array of expected entries
Map.Entry[] expected = new Map.Entry[size];
for (int i = 0; i < size; i++) {
// generate a random key
String key = Util.randomString(10);
// in case the key is already in the map, retry
if (actual.containsKey(key)) {
i--;
continue;
}
// generate a random value
String value = Util.randomString(10);
// put the entry in both the actual map
actual.put(key, value);
// ... and the expected entries
expected[i] = Map.entry(key, value);
}
return new Object[] {actual, expected};
};
static AssertionRunner runner = s ->
assertThat((Map) s[0]).containsExactly((Map.Entry[]) s[1]);
public ContainsExactly() {
super(provider, runner);
}
}
For this purpose, we use the classes with the lowest code health. As examined in a previous essay, these are the classes focused on complex data structures with many custom assertions. The three classes we chose are Iterables, Maps, and Strings. These all vary conceptually but are commonly used in software and are thus good candidates to obtain realistic and relevant results. We used the same specific implementation for all the assertions relating to the classes: ArrayList of Integer for the Iterables (due to its common usage), and LinkedHashMap of String (key and value) for the Maps (due to the fact that it stores the keys in a sorted way).
In total, we ran experiments for 82 assertions - 56 for Iterables, 18 for Maps, and 8 for Strings. Each assertion is run for different input sizes. For assertions in Iterables and Maps, this is the number of entries and for Strings the number of characters. The input size ranges from 10.000 to 200.000 with increments of 10.000. These numbers were chosen to be able to measure the growth of the runtime, while still keeping the total running time of the experiment manageable. Each assertion is run 30 times for each input size to get a consistent result despite the randomness of the data generation and influences from the system the experiment is run on. When a single run of an assertion takes longer than 15 seconds, the experiment for that assertion is terminated. All experiments are run on an AMD Ryzen 5600X with 16GB of RAM.
Given our setup, we predicted we could randomise the input and obtain objective findings for a complete set of assertions. On the other hand, if we had wanted to investigate scaling the number of assertions, it would be non-trivial to determine which assertions would be run. Using test suites from existing open-source projects would not cover the entire codebase but simply running all of the assertions does not directly translate to AssertJ Core’s performance in practice. Therefore, scaling the number of assertions would require further investigation into the kinds of assertions that are being used in industry, while scaling input size provides direct and objective results of AssertJ Core’s implementation.
Results
For each assertion, the median and the standard deviation were plotted. Depending on these plots we determined the general trend the runtime follows. In the following three figures, we show examples of different identified trends.
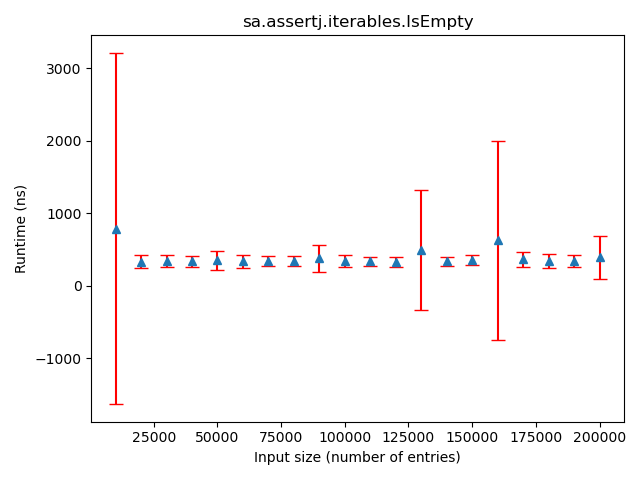
Figure: Example of an assertion with a constant trend
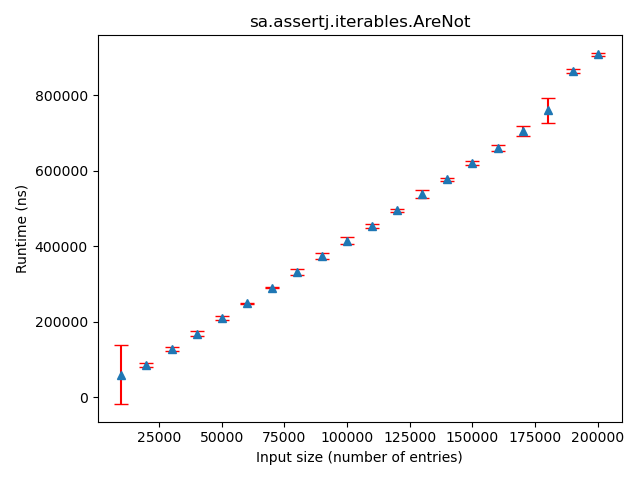
Figure: Example of an assertion with a linear trend
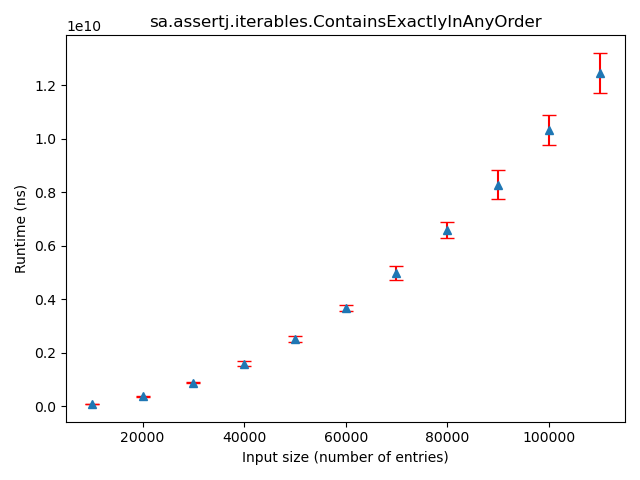
Figure: Example of an assertion with a polynomial trend
From now on, we use m to denote complexity with respect to the size of the actual variable and n to denote complexity with respect to the size of the variable used in the assertion. For better understanding, the two variables would appear like this in an AssertJ assertion:
assertThat(m).containsAll(n);
The following table is a summary of the 15 assertions for which we expected a certain complexity but obtained different results. For all the remaining 67 assertions we tested, we obtained the expected results. All of the raw data and the generated plots can also be found in the experiment’s repository.
| Class | Assertion | Expected Trend | Actual Trend | |
|---|---|---|---|---|
| 1 | Iterables |
AnyMatch | Linear (O(m)) |
Constant |
| 2 | Iterables |
AnySatisfy | Linear (O(m)) |
Constant |
| 3 | Iterables |
ContainsAll | Polynomial (O(mn)) |
Inconclusive (high std) |
| 4 | Iterables |
ContainsAnyElementsOf | Polynomial (O(mn)) |
Inconclusive (high std) |
| 5 | Iterables |
ContainsAnyOf | Polynomial (O(mn)) |
Inconclusive (high std) |
| 6 | Iterables |
ContainsExactly | Linear (O(m)) |
Polynomial |
| 7 | Iterables |
HasExactlyElementsOfTypes | Linear (O(m)) |
Polynomial |
| 8 | Iterables |
StartsWith | Linear (O(n)) |
Constant |
| 9 | Maps |
ContainsEntry | Linear (O(m)) |
Constant |
| 10 | Maps |
DoesNotContainValue | Linear (O(m)) |
Polynomial |
| 11 | Strings |
IsBase64 | Linear (O(min(m, n))) |
Constant |
| 12 | Strings |
IsGreaterThan | Linear (O(min(m, n))) |
Constant |
| 13 | Strings |
IsGreaterThanOrEqualTo | Linear (O(min(m, n))) |
Constant |
| 14 | Strings |
IsLessThan | Linear (O(min(m, n))) |
Constant |
| 15 | Strings |
IsLessThanOrEqualTo | Linear (O(min(m, n))) |
Constant |
We will now briefly address the causes of these discrepancies.
- Assertions 1-2: For these two assertions, we implemented a non-representative generator which caused that an element satisfying the condition would always be found very early on in the iterable.
- Assertions 3-5: These assertions had a large runtime and were thus often terminated after our predetermined 15 seconds. This resulted in insufficient data which caused high standard deviation and thus inconclusive results.
- Assertions 6-7: In these implementations, AssertJ Core uses suboptimal implementation which we explain in the discussion. This results in a polynomial (
O(mn)) runtime even though it is not necessary. - Assertion 8: Here we again used a too specific generator which always created starting sequences of only one element. This resulted in constant time instead of the linear growth proportional to the expected starting sequence size.
- Assertion 9: For running all of the
Mapsassertions, we used aLinkedHashMap. This data structure has a constant complexity for all its lookup functions and we thus received an unexpected constant time for this assertion. Had we used a different implementation ofMapwhich has a slower lookup time, the graph would have been linear. - Assertion 10: As seen in the figure below, the deviation of the larger input sizes made it hard to determine whether the runtime is linear or polynomial. We would thus need more data to draw conclusions here.
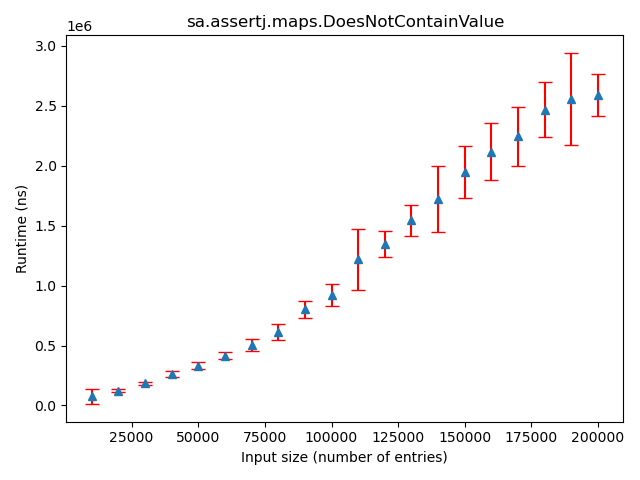
Figure:
Actual trend for doesNotContainValue in Maps
- Assertion 11: The expected trend here was linear and while the first plot created from raw data was constant, it turned out to indeed be linear after removing the outlier in the middle.
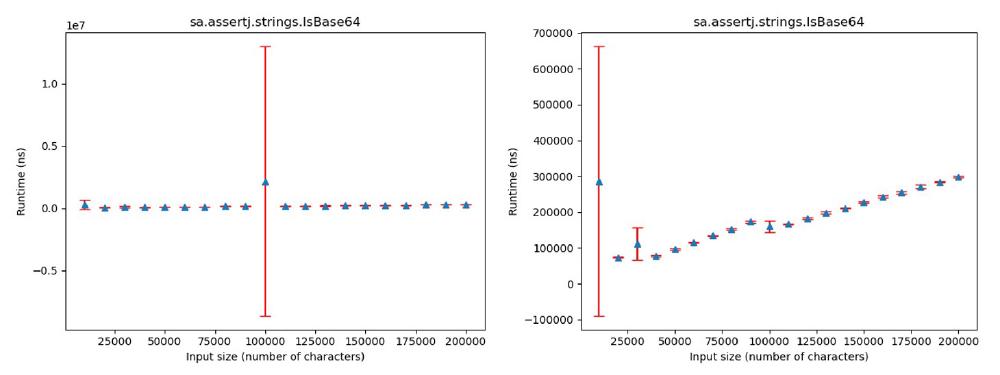
Figure:
Raw data (left) and without outlier value (right) for isBase64 in Strings
- Assertions 12-15: Finally, we unfortunately made the generators for
Stringstoo random and thus a difference was almost always found in the first character, resulting in the unexpected constant runtimes.
Discussion
As a general conclusion from the results, we can claim that AssertJ Core has very little unexpected runtime issues. As we already reasoned in our previous essays, the architecture and coupling between the components is simple enough to support scalability. This is also supported by the fact that for the big majority of the assertions we tested, the runtime behaved as expected.
While we cannot suggest any improvements to the architecture, our experiment revealed a possible point of improvement when it comes to some specific assertions such as containsExactly or hasExactlyElementsOfTypes. The current solution first checks that there are no unexpected elements and no missing expected elements and only then performs an element-wise comparison of the actual and the expected value. The preliminary checks are both polynomial (O(mn)) since they are also meant to work for comparing iterables regardless of ordering. We instead suggest an approach which does a simple constant check on the equality of the sizes of the two iterables and then linearly compares their elements. A pseudocode implementation is given below:
boolean compare(expected, actual) {
if (expected.size() != actual.size()) return false;
for (int i = 0; i < expected.size(); i++) {
if (expected.get(i) != actual.get(i)) return false;
}
return true;
}
We also suggested this change in an issue and got a response from one of the maintainers that he thinks it can and should indeed be improved.
With that in mind, the design of our experiment was suitable in finding weak spots but was insufficient to determine whether any architectural changes should be made. Given that we do not suggest any changes in the architecture, we recommend interested readers to read our essay on AssertJ Core’s architecture for an overview (which is why we also do not include the diagrams here).
Furthermore, to discuss the performance of AssertJ Core in a broader context, it is insightful to circle back to an experiment mentioned in the introduction. This was an experiment that compares the performance of the same test suite using JUnit and AssertJ Core assertions, focusing on the runtime and energy consumption1. It is relevant because while we have now determined that AssertJ Core’s runtime grows proportionally to the input sizes of the objects we are asserting on, we still need to determine whether the runtime is acceptable in absolute terms.
This experiment shows that the runtime of a test suite using AssertJ Core is 13% slower than that of a test suite which uses native JUnit assertions1. Note that this comparison focuses mostly on simple assertions such as isEqualTo which might not sufficiently showcase AssertJ Core’s strengths. On a test suite that would run for 120 seconds using JUnit, AssertJ Core assertions would introduce a slow-down of approximately 16 seconds. This can be a significant increase when resources are tight, but in most cases it is still within acceptable bounds. In the end, it is up to each developer to see whether this increase in runtime is an acceptable cost for AssertJ Core’s assertions.
Conclusion
Throughout this essay, we have shown that testers need to make a choice between the clarity of AssertJ Core and the speed of JUnit. Luckily, AssertJ Core scales at an expected rate. This means that AssertJ Core is a library which satisfies the requirements of its various stakeholders including, in most cases, that of scalability. In conclusion, AssertJ Core is a mature assertion library with a simple architecture and a rigorous quality culture, resulting in a product of high quality.
References
-
Jirovská, H., & Juhošová, S. “AssertJ: How Green Is Your Test Suite?” Sustainable Software Engineering, 3 Mar. 2022, https://luiscruz.github.io/course_sustainableSE/2022/p1_measuring_software/g5_assertj.html. ↩︎