Running Checkstyle on Larger Projects
Scalability is about being able to handle more work without this causing issues. For most software, scalability is about the number of people using it. If a million people suddenly open your website at the same time, your server should be able to handle this. As Checkstyle is only run locally or as part of a continuous integration pipeline, this aspect of scalability is not an issue. What can however grow, is the size of the project Checkstyle is run on, and the number of checks to be run. In this essay, we will talk about the scalability of Checkstyle. Firstly, we will look at the key scalability challenges. Secondly, we will discuss some experiments to see how well Checkstyle scales. We will then consider how Checkstyle’s software architecture influences its scalability. We will also suggest potential improvements to alleviate problems regarding dealing with larger numbers of files.
Key Scalability Challenges
For Checkstyle, the amount of work is primarily determined by the size of the project it is run on. We have identified several relevant factors: the number of files to check, the length of these files, the complexity of the files, and the number of checks to execute. The first three depend on the project files, while the last one is based on the configuration Checkstyle is run with.
Firstly, let’s take a look at the projects that use Checkstyle. The tool is built for Java projects, and many large systems are built in this language. Android apps, back-ends of major services like Amazon, and video games are often written in Java and use Checkstyle. Generally, Java projects scale mostly by number of files: according to the first criterium in the SOLID principle 1, a class should only have a single responsibility. That means classes should not become more complex when the project does. Looking at running Checkstyle on larger or more complex files would be something that could be interesting to explore, but this quickly loses its connection with reality; single files often go up to several thousands lines of codes in extreme cases, but anything more than that is simply not realistic.
Checkstyle comes with 184 built-in checks 2. Developers of systems can extend Checkstyle by adding their own checks if they want specific functionality that is compatible with Checkstyle. However, these few extra checks that developers may implement, and the few extra checks that may be added to Checkstyle by the development team, will not change the scope significantly. The implementation of how these checks are run is still important for the performance of Checkstyle however, even if it is not expected to scale up to more checks.
Empirical Quantitative Analysis
Usually, Checkstyle is integrated as part of a continuous integration (CI) pipeline. While the servers responsible for executing projects’ pipelines are not necessarily low-end, they do tend to be responsible for vast amounts of pipeline executions, possibly from different projects, hosted on different locations. Therefore, the computational resources that a pipeline can use on a CI server are often severely restricted.
In our test for the effects of resource limitations on Checkstyle, we consider the restriction of both processor time and memory. With regard to processor time, restricting this severely could result in longer waiting times for pipeline executions. While this could be somewhat annoying, most such executions take quite long already, and people do not tend to wait on them (instead, they just do something else and check later if everything went according to plan).
In contrast to processing time, where scarcity of it would simply result in longer waiting times, a shortage of memory could have more extreme implications, such as crashes or even just freezing a system completely. We investigate the minimal amount of memory required to do a certain job by starting at N megabytes of RAM, and increasing this by 2 for every time it fails. To simulate different workloads, we create three different projects; Checkstyle_small, Checkstyle_medium, and Checkstyle_large. Here, Checkstyle_large is simply Checkstyle as a whole, where Checkstyle_small and Checkstyle_medium are random subsets of the files Details about the three projects, along with the results of the experiment, can be seen here:
| Test name | Number of files | Required Memory (RAM) |
|---|---|---|
| Checkstyle_small | 43 | 12MB |
| Checkstyle_medium | 204 | 32MB |
| Checkstyle_large | 454 | 44MB |
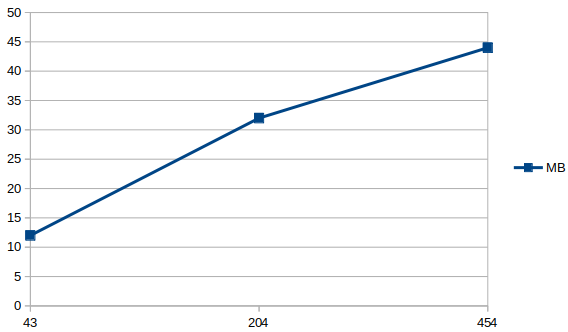
Figure: Minimal memory required for different project sizes. Horizontal axis: number of files. Vertical axis: minimum MB needed.
In the graph, we observe an almost linear relation between the number of files and the minimal required memory. This could be the logical consequence of loading and parsing all files into memory, as well as having to do with a larger subset having a higher probability of containing large or difficult to analyse classes.
We investigated the implications of restricting Checkstyle to its minimal required amount of memory. A comparison here is made on Checkstyle_large runtime, where the memory cap is set at 64MB and doubled each time.

Figure: Runtime of Checkstyle under constraint of different memory limits.
Here, we can conclude that even though Checkstyle runs slightly faster with more memory available, we do not consider the difference in runtime significant in the sense that we would call the higher amount of memory a requirement.
It is clear that 44MB of RAM is enough to run Checkstyle on its own source code, and that increasing the memory availability does not offer significant benefits. Since CI servers nowadays have several GBs of RAM, memory restrictions should not be considered problematic in realistic scenarios.
Architectural Decisions that Influence Scalability
As discussed in our essay Checkstyle: Architecture for Extensibility, Checkstyle makes heavy use of the visitor pattern. To recap, instead of running checks directly on source code, Checkstyle runs most checks on the abstract syntax tree (AST). Checkstyle has many checks that need to run on the same file, so ideally this tree should only be built once. The visitor pattern allows for checks to be run independently, without modifying the AST. This pattern is ideal for scalability: with more checks or larger files, the runtime of the system scales linearly.
One other major design decision made that influences scalability for the better is the fact that Checkstyle can only run checks on singular files separately. This means that checking the connections between files, like e.g. coupling between classes or checking whether public functions that aren’t called by other classes could be made private, cannot be run using Checkstyle. It does however make it so that in larger projects with more files, Checkstyle can scale better. If interconnections between files had to be checked too, the time complexity could grow faster than linearly with the number of files.
Overall, while Checkstyle of course takes longer when more checks, longer files, and more files, the system architecture and the visitor pattern allow for a fair linear scaling with respects to these factors. There are however still some things that could be improved.
Potential Improvement
Before we go over a potential improvement for the Checkstyle project, it is important to understand the structure of its classes.
Class Hierarchy
The top-level classes of our interest are the interface FileSetCheck and its partial implementation AbstractFileSetCheck.
These classes represent checks that will be executed based on the contents and metadata (e.g. filename) of a file.
Examples of such checks are the check for line lengths or filename formats.
There is one special subclass of this check: the TreeWalker.
This class can store various instances of AbstractCheck, which is a check that operates on nodes of the AST.
The TreeWalker class first creates an AST from the file text, after which this tree is traversed.
During the traversal, all checks are executed on each node. See the figure below for a diagram of these classes.

Figure: The current state of the Checkstyle class hierarchy
Inefficiency
The problematic part lies in the fact that AbstractChecks still have access to the textual contents of the file.
Some checks, for example the JavadocMethodCheck and UnusedImportsCheck, use this text to complete their checks. However, searching through the file contents could be very inefficient and should thus be avoided.
For this reason, tests should use the AST; these AST checks are designed to use the visitor pattern, which prevents this inefficiency.
The Checkstyle team noticed this problem too, and they opened an issue to resolve it.
For now, the method getFileContents() is marked deprecated, and all methods using it suppress a warning for this.
However, this will not be an easy fix as the Checkstyle team also noted; they say that “updates are not simple and there might be breaking changes or some kind of new functionality.” (romani on GitHub)
Potential Solution
In the aforementioned issue, the Checkstyle team proposed to remove the use of getFileContents() in full.
However, this method returns more than just the file text: it also provides the metadata.
For that reason, checks like OuterTypeFileNameCheck, which verifies whether public class Foo is in a file called Foo.java, still requires access to this metadata.
Such checks cannot be run using only the AST, they require a combination of both the AST and the file metadata.
The solution described by the Checkstyle developers is to transform the checks into pure AST checks.
These checks would then be ren using the visitor pattern, making them more efficient.
While this idea could work for a number of these checks, there are also some checks that require data that is not present in the AST.
A solution for such cases, e.g. the OuterTypeFileNameCheck, has not been provided or suggested yet.
Currently, the getFileContents() method returns a class named FileContents. We think it would be a good idea to create a new class
This new class would still contain the file’s metadata that is required, but not the textual contents.
Such a class is easy to integrate into the project: the AbstractChecks should no longer have a FileContents as attribute, but an instance of this new class.
In the diagram below, these changes are reflected
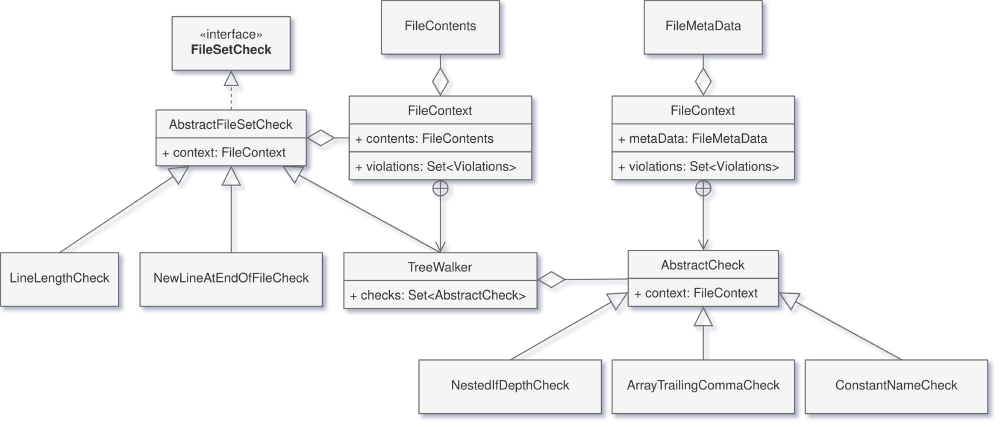
Figure: A potential improvement to the state of the Checkstyle class hierarchy
Without causing a big restructure, using a new class can avoid this problem from occurring more often by simply disallowing access to the problematic part, the text in a file. This would still require all existing cases to be fixed, but after this it can be ensured to never happen again without requiring reviewers to point this out.
Conclusion
Due to several clever architectural decisions, the run time of Checkstyle scales almost linearly with the codebase it is run on. It is fairly efficient with memory as well, meaning that overall there is not a lot of room for improvement.
There are a few checks that have an inefficient implementation, which should be resolved.
This may require a change to not only these checks, but also the AbstractCheck class, the superclass of all AST checks.
All in all, the Checkstyle project is a clear-cut example of a mature project with an architectural design greatly influencing its efficiency.