Egeria: From Vision to Architecture
Introduction
In our previous essay we focused on the product vision and the underlying problem Egeria is trying to tackle. Now we will see how this product vision translates to the Egeria architecture, and with what underlying principles that architecture was designed and how it evolved.
We will start with a general overview of the systems architecture with the design trade-offs, followed by a more in-depth discussion of the architecture through different views and the Egeria API.
The Architecture
The current design of Egeria stems from a collaboration between IBM and ING. They wanted to connect their isolated data centers to a centralized system. This would allow them to make better data-driven decisions, hopefully leading to more successfull businesses. The original implementation of Egeria consisted of a datalake based on IBM technologies where all tools could be connected to.
However, this initial concept created by IBM required all services to be integrated and working on the same type of definitions, namely those of IBM. Although IBM opened up APIs to allow other services to connect this still created a dependency on third-party vendors to implement these specific IBM APIs. The solution was to create a general open-source metadata exchange system that everyone could extend to suit their needs 1. This idea helped form the main architectural design principles of Egeria, which we will discuss below. We go over each of them briefly, for more in-depth insights we would like you to refer you to this video, which is an excellent keynote by one of the Egeria developers.
Egeria tries to be autonomic, meaning that the system requires as little human intervention as possible. Think of system properties like self-configuring, self-validating, and self-optimizing. An example would be Egeria’s audit log framework. This information is helpful for automatic error solving.
Egeria is quite strict on allowing new dependencies. This strictness ensures it is integratable in many different environments.
Another major design decision is to separate the server from the platform it is running on. This adaptability allows Egeria to run on a raspberry pie or run distributed with Kubernetes on many big servers.
Egeria also provides a great number of built-in metadata types. These metadata types are extendable, as a type system can not cover every possible metadata type. This makes the system extensible. Those changes can be kept private or contributed to the open-source type system. In a conflict between private and public types, the public types take priority.
A fair ecosystem is also one of Egeria’s main design principles. Egeria allows vendors to show that they are a part of Egeria. To accomplish this they can add an Egeria mark to their products. However, any customer has the right to download and run a demo/test case showing the product is compliant with Egeria’s standards.
To have a trustworthy data governance system, it is essential to enable users to control who can see or access your data and have a secure platform. Egeria allows for very fine-grained access control by checking access in multiple steps and even allowing users to set visibility on an attribute level. This level of control could be necessary if even knowing that certain data exists poses privacy or security risks.
For Egeria to function everywhere it needs to be inclusive as some environments might require 40 years old technology to communicate with brand new software. Egeria has two different access services to accomplish this. The open metadata repository services are low-level and difficult to understand but allow fine-grained access. The open metadata access services instead allow easier access using prebuilt connectors. These repository services allow all these technologies to connect correctly to Egeria
Open metadata governance and exchange is a relatively young field. The team working on Egeria discovers new things all the time, requiring them to be innovative. That is why Egeria finds it important to be educational, and help others learn about metadata and governance. To do this they run a dojo where partitioners learn how to use the system, and they have examples of a fictional company that wants to become more data-driven 2.
Design trade-offs
As explained in the previous section, the main principles that Egeria is built on are integrability, autonomic, and extendibility. As with all project it is impossible to design a perfect system, and these principles all come at a cost requiring trade-offs to be made. An example of a trade-off involving the autonomic principle is the fact that the development team is very strict on introducing new dependencies. This can only be done in the case where it is absolutely needed as they value ease of deployment and use higher than the added benefits to development these dependencies could bring. Also during one of the weekly developer calls we attended, a discussion took place regarding a piece of code that performed checks related to security. Someone brought up the fact that these checks are ,in some cases, redundant and removing them could significantly speed up the system. After a healthy discussion they concluded the systems security was priority, even if this was at the cost of response time. They assigned a developer to see whether this performance loss could be reduced to specific use cases.
Container view
The following sections describe in detail the inner workings of Egeria. We start from a high-level overview of the entire system and then dive deep into specific components.
Egeria is a distributed system, meaning it is not managed centrally, but rather it is interconnected with multiple other servers 3. In figure 13 you can see what such a system looks like 4. The green clouds represent servers on which systems are deployed. On such a server, it is possible to have multiple running components, represented by the grey boxes. A blue box represents an Egeria server platform. These platforms are interconnected with each other if configured to cooperate. If the servers should cooperate, they are in the same cohort having the same meta-data definition and integration test framework.
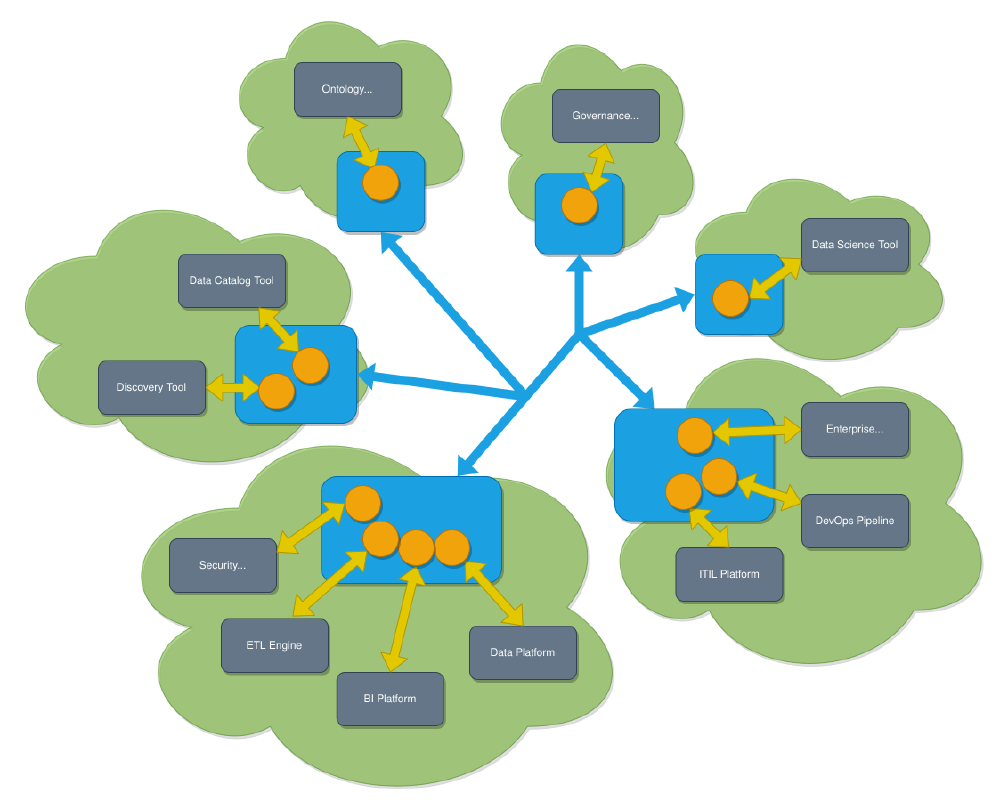
Figure: Figure 1 - Example distributed network Egeria
The framework of these Egeria server platforms (blue box) can be seen in figure 25. In such a server platform, there are multiple services provided. Egeria provides some services to maintain the platform, administrative services, and metadata governance services. A platform can run one or more Open Metadata and Governance (OMAG) servers (orange circles) concurrently. The OMAG servers are the interface from which many of the other Egeria functionalities inherit. Each of these services and the OMAG servers can be deployed separately, but fulfil a specific role in the overall deployment landscape.

Figure: Figure 2 - Egeria server platform
Component view
As stated before, in an Egeria server platform, multiple OMAG Servers can be run. This concurrency provides many of the functionalities of Egeria. The components that inherit from the OMAG Server can be seen in figure 36. Below important servers are discussed in more detail.
Metadata Access Server This server manages the metadata repository and supports access services.
Repository proxy The proxy is the interface between Egeria and a third-party metadata repository.
Conformance test server This server validates whether a member of the cohort is conforming to the cohort protocols.
View server This server manages the services which are relevant for the user interface
Governance server This server supports the use of metadata across different IT landscapes. Responsibilities include synchronization, data capturing, and managing lineage information.
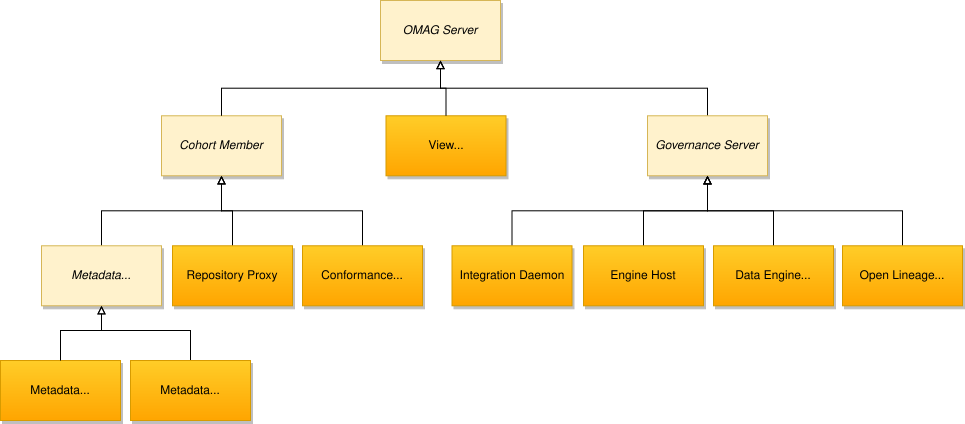
Figure: Figure 3 - Types of OMAG servers
Connectors view
After explaining the components themselves we will now discuss the connection between components. As the server platform is highly configurable, there are many different setups. In figure 4 we use an example to show how the different components are connected.
Users can interact with the system through the view server. The view server is connected with the governance server to manage the metadata integration and additional governance activities. Similarly it is also connected to the metadata access server to collect the metadata.
The Metadata Access Server (MAS) is connected to most other OMAG servers. The connection to the governance server is to enable the managing activities to be performed on the metadata. To that end, the MAS is also connected to the metadata repository.
When different server platforms want to connect, they have to be in the same cohort. In figure 4, The proxy repository can only be connected to the MAS server because they have the same cohort.
Lastly, Egeria provides the possibility to add third-party technologies to most OMAG servers. In the example, the third-party software can be used to add additional governance actions, extend the UI in the view server or perform actions directly on the MAS.
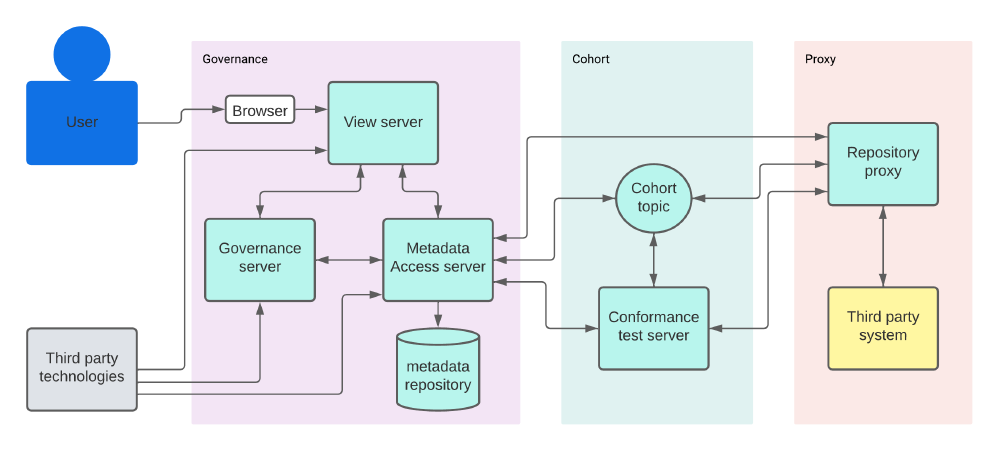
Figure: Figure 4 - Egeria example connection network
Development view
The Egeria project is split into multiple repositories. These consist of connectors, commonly used in systems such as Hadoop and XTDB, dev projects, documentation, and the main Egeria repository. To help developers get started with Egeria, the team has set up an extensive training, called the Dojo7. Here they explain in detail how to get your system set up for use and development of Egeria.
The Egeria runtime and clients are written in Java8 and the IDE recommended by the developers is IntelliJ IDEA. Besides Java, Egeria also uses some Python. This is not used in back-end implementation but there are some examples on how to connect to Python environments as well as hands-on labs to learn working with Egeria which makes use of Jupyter Notebooks. To handle the building of the project, the team uses Apache Maven (and is currently working on moving to Gradle)9.
The implementation of Egeria is split into different modules, of which details can be found on the GitHub. Due to the nature of the open-source project and an agile workflow different modules are constantly under development and new code is introduced regularly. In order to keep all of this clean and organized the maintainers have created a streamlined status system for the different modules10.
Next to implementation, another important part of development is testing. Egeria recognizes this and applies two different types of tests on their codebase. These are unit tests, using TestNG and Mockito and Function Verification Tests (FVTs). There is also a test suite to check conformance for connectors11.
Run time dependencies
Although being a complex system, reserved decisions have been made with regards to the requirements and components needed at run time. The developers are vigilant about introducing new runtime dependencies, as Egeria needs to be embeddable meaning it can not rely on a huge amount of, sometimes platform/container-specific, dependencies 1.
The most prominent dependency is the event bus, used to connect the different Egeria instances. In Egeria, the default is set to be Apache Kafka. Now while Apache Kafka is the default it is by no means irreplaceable and implemented through a connector with Egeria 121. Otherwise, there are no other dependencies that are strictly required 13.
During runtime the system is of a very flexible nature, as also discussed in the component and container view sections. Different servers consisting of different components and underlying third-party tools, connected to each other in a cohort sharing and receiving metadata.
API design
The APIs are an important aspect of the Egeria ecosystem. One of the main goals of Egeria is to allow metadata to be shared across different data platforms and to tools of different vendors14. To achieve this it is required to have a strong API to allow users to connect their different systems to the Egeria ecosystem.
The APIs provided by Egeria can be split into the following three categories15:
- APIs to configure Egeria
- APIs to operate Egeria
- APIs to work with open metadata and governance
It is possible to directly call the REST APIs which is an industry standard 1617, or to call the Egeria API by connecting to the event bus through for example Apache Kafka18.
Backward Compatibility
Egeria tries to ensure backward compatibility in its APIs between releases whenever possible. If it’s not possible to provide backward compatibility in a news release it will be explicitly mentioned in the release notes with instructions on how to upgrade19.
Conclusion
While being a complex system, one could definitely argue that Egeria has a very clear design philosophy, throughout the whole architecture there is a focus on extendibility, flexibility, and ease of use. Egeria tries to perpetuate itself as being open trustworthy in part as an effort to increase adoption.
References
-
https://www.youtube.com/watch?v=n-Xm8_WIyBM&ab_channel=MandyChessell ↩︎
-
https://egeria-project.org/introduction/egeria-distributed-operation.svg ↩︎
-
https://egeria-project.org/guides/planning/guide/#platforms-and-servers ↩︎
-
https://egeria-project.org/concepts/omag-server-platform/#inside-the-omag-server-platform ↩︎
-
https://egeria-project.org/concepts/omag-server/#platform-url-root ↩︎
-
https://egeria-project.org/guides/contributor/development/#apache-maven-and-gradle ↩︎
-
https://egeria-project.org/guides/contributor/guidelines/#write-tests ↩︎
-
https://egeria-project.org/connectors/resource/kafka-open-metadata-topic-connector/ ↩︎
-
https://egeria-project.org/education/egeria-dojo/developer/different-types-of-apis ↩︎
-
https://www.slideshare.net/CloudElements/state-of-api-integration-report-2017 ↩︎
-
https://en.wikipedia.org/wiki/Representational_state_transfer ↩︎
-
https://egeria-project.org/education/egeria-dojo/developer/overview/#dojo-activities ↩︎
{kind=link}