Essay 4
Identification of the system’s key scalability challenges under a plausible scenario.
Ghidra’s time performance
Ghidra is a Software Reverse Engineering (SRE) framework, which includes a suite of full-featured, high-end software analysis tools that enables users to analyze compiled code on a variety of platforms, including Windows, macOS and Linux as described here. Therefore it is not really designed to be used on systems like tablets/phones. Even if these devices were capable of running Ghidra, it would not have been very useful, since analyzing code on small screens is not very user friendly. Ghidra’s installation guide even suggests using two screens.
Regarding computer components, Ghidra mostly relies on the CPU and a little bit on the main memory of the system (at least 4GB according to the minimum requirements). Ghidra does not have any specific CPU requirements in its minimum requirements. A GPU is not needed for Ghidra, since Ghidra does not rely on any graphical processing.
The task manager shows that when analyzing a newly imported binary to Ghidra, that it only uses a single core to do this, and that thus, Ghidra probably does not use multithreading really well. Even if larger binaries are analyzed with Ghidra, it still uses only a single core to analyze it. This causes it to take a lot of time with larger binaries as we will see later. This thus means that if we would use another processor with fewer cores, but the same single-core performance, Ghidra would probably take the same amount of time to analyze the imported file. However, taking another processor with more cores, but with a worse single-core performance would thus mean that Ghidra would take a longer amount of time to analyze the imported file.
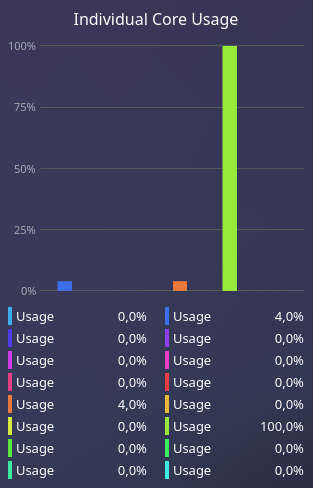
Figure: Ghidra only using a single core to analyze binaries
As explained earlier, Ghidra takes a lot more time to analyze large binaries. We came to this conclusion after analyzing binaries of different sizes. First of all we started with the easy_reverse crackme on crackmes.one. Ghidra analyzes this binary instantly (its size is only 16.4KB), and did this so quickly that we could not measure the time that this took. The second binary we analyzed was the Notepad++ (v8.3.3) executable for Windows. The size of this executable was 4.2MB. Analyzing this took 9 seconds. Finally we analyzed the bitcoind binary that can be downloaded in the release file of Bitcoin core v22.0. The size of this file was 12.3MB, but analyzing it took around 7 minutes and 40 seconds. We think that this is not only because the binary’s file size is almost three times as large, but also because the bitcoind binary is much more complex than the Notepad++ executable since it is a program that implements the Bitcoin protocol for remote procedure call (RPC) use[^bitcoind-rpc].
Ghidra’s space performance
When analyzing binaries, Ghidra uses around 4GB of RAM. This amount of RAM is also the minimum requirement given in the installation guide. Ghidra’s whole installation is around 940 MB. This amount is also the same as listed in the installation guide. Furthermore the project files of each of the imported binaries also takes up some extra storage. The project folder of the easy_reverse crackme, that was originally 16.4KB, is 1.2MB, the project folder of Notepad++ is 5.5MB and the project folder of bitcoind is 15MB.
Empirical quantitative analysis under varying workloads of at least one scalability dimension that can limit scalability
Now that we have got the times of how long it took to analyze each binary/executable, we will do the same with limited resources. To limit the resources of our system, we will use stress, which creates a synthetic CPU load. We will do this for all 16 threads on the computer that Ghidra is being runned on, with the -cpu 16 option when running stress. Analyzing the easy_reverse crackme now took 5.5 seconds. Analyzing the Notepad++ executable took 17 seconds, and analyzing bitcoind took 9 minutes and 30 seconds. This data indeed confirms that Ghidra is very CPU reliant, and that having reduced resources, impacts the performance of Ghidra drastically, as the amount of time it took to analyze binaries increased and sometimes even more than doubled. The data comparing the analyzation time with and without load can be seen in the graph below.

Figure: Comparing the time Ghidra took to analyze various binaries with and without extra CPU load
Architecting for scalability
We will now look at how certain architectural decisions affect the scalability of a project and how this affects Ghidra in particular. Let us first consider what it means for the architecture of a system to be scalable. A software project is considered to be scalable if the system can adjust to, and handle a sudden increase of load. Within the field of software architecture, we often speak of vertical and horizontal scalability. Scaling up a system vertically means to deploy it on a computer with a higher capacity, i.e. faster CPU, more RAM, or more storage. Horizontal scaling, on the other hand, means to deploy your system on multiple computers that do not necessarily have a higher capacity.
While the first of the two may seem easier to achieve, we could simply encourage people to run the Ghidra software on a better computer, it may be more interesting to argue about the second of the two. Ghidra takes binaries and decompiles them back to source code, and when these binaries get large, the time it takes to do this increases significantly. One way to approach this issue is to look at how we can realize horizontal scaling.
Realizing horizontal scalability in Ghidra
Horizontal scaling can be realized through task parallelization. In Java, to parallelize tasks, we can make use of multithreading, that is, to make use of several threads on a single CPU. As we have observed in the paragraph on Ghidra’s time performance, Ghidra does not do this sufficiently.
If we can take this task of decompiling a binary, and split it into smaller tasks, we can execute them in parallel to decrease the execution time. A similar idea is to put the target application file on a distributed system to maximize its performance. However, this approach is bound to be more expensive to implement. Amdahl’s law gives us a theoretical upper bound on the speedup we can obtain this way:
S(n) = 1 / (1 - P) + P/n
S(n): the speedup achieved by using n cores or threads.
P: the fraction of the program that is parallelizable.
(1-P): the fraction of the program that must be executed serially.
Current and Future Architecture Design and Why They will work
Multithreaded loading: We now know that Ghidra uses a single CPU core when loading projects. This will significantly affect Ghidra’s scalability, as if Ghidra will continue to use only a single core when loading large projects, it will make using larger binaries nearly impossible. In order to deal with this problem, we propose that a possible follow-up development direction for Ghidra is to develop multithreaded application loading functions, so that each time a project is analyzed, multiple cores of the processor can be used, which maximizes the use of the computing power of the computer, which results into a better performance of Ghidra. Therefore, starting the parallelization of the loading phase can further increase the level of parallelization and improve the scalability of Ghidra. Distributed system: Although Ghidra has a Ghidra server feature similar to Git, the current operation mode decompilation is still on a single machine. Distributed systems can greatly improve the efficiency of decompilation. However, the operation of decompilation tasks on distributed systems still needs to be further developed. Possible future work includes the guarantee of distributed consistency, the division of tasks that can perform distributed processing, etc.
Based on the Amdahl’s law described in the above section, we can approximate how much speedup can be achieved if Ghidra is improved with multithreaded functions or with a distributed system. For instance, suppose 40% (It is still not clear what exactly will this number be, to the best of our knowledge) of the decompiling work can be done by task parallelization, and we manage to utilize 8 CPU cores, then the speedup will be approximately 154%, which is an improvement greater than 50%.

Figure: Comparing the current and future design on processor usages

Figure: Distributed Ghidra