PMD - Scalability
Scalability is a system’s ability to meet its quality requirements in the presence of some strain on the system, such as increased workload or reduced resources. In this essay, we will explore the current performance of PMD at scale and propose reasonable changes to improve the scalability of PMD:
- PMD’s Scalability Challenges
- Scalability Quantitative Analysis
- PMD’s Scalability Concerns
- In Practice - Feasibility Check
- Testing the Improvement - Validation Procedures
- References
PMD’s Scalability Challenges
The PMD static code analysis tool is used in various contexts that each have unique scalability challenges. Users can use PMD standalone through the command-line interface (CLI) or as part of a continuous integration (CI) pipeline. PMD can also be integrated into IDEs and build tools through plugins. In the standalone configuration, PMD’s quality requirements are relaxed: time and resource consumption can be high without breaking functionality or too much negative effect on user experience. Developers are already used to waiting for tests to run upon code bases for up to minutes. One caveat of the standalone approach is the execution environment. PMD in CI pipelines typically has access to reduced computational resources, as CI configurations often use hardware or virtual machines with reduced memory and CPU power.
As a plugin, quality requirements are more strict than standalone, as there are soft limits to response time caused by live syntax highlighting. Users of PMD as an IDE plugin expect it to respond automatically and quickly, and failure to do so breaks the functionality of the tool as the developer may not see a warning if it takes too long or may disable or ignore the plugin.
Under both scenarios, however, PMD’s crucial scalability dimension is time. Even in the more relaxed setting of standalone operation, users may switch to a more performant alternative if PMD takes an extreme amount of time to complete.
While PMD benefits from forgiving scalability requirements, it has swiftly increased workload complexity. PMD performs static code analysis per file and per rule: each file must be loaded and parsed into an abstract syntax tree (AST), and then every relevant rule must be checked against that AST. As the number of and complexity of files and rules increases, workload complexity quickly becomes extreme.
Scalability Quantitative Analysis
Due to PMD’s workload complexity, PMD has many mechanisms to split the workload efficiently. One is multi-threading, where PMD can analyze each file in different threads. Another is multiple caching layers, wherein only files that have changed since PMD’s last execution are analyzed. In addition, rules that check similar constructs do not need to re-search the AST to find them.
PMD includes a built-in benchmarking tool that reports PMD’s execution time, including per-phase (such as file loading and abstract tree building) and per-rule timers.
Figure:
Sample PMD Benchmark Output

As PMD runs in various environments, we perform benchmarking experiments to measure the analysis time of PMD in multiple typical execution environments. Using an Ubuntu virtual machine (VM) image, we run PMD 6.43.0 on the source of PMD (as of March 11, 2022)1 using all of PMD’s built-in java rules2. We duplicate this source code to create double and quadruple workloads to increase the workload complexity. For VM sizing, we run the benchmark with 1, 2, 4, and 8 vCPUs. Notably, running PMD in a limited VM is a typical execution environment for CI pipelines. Github Actions is a widely used CI tool3, and it uses Microsoft Azure’s “Standard_DS2_v2” virtual machines4, which have two vCPU and 7GB RAM 5. The results of our benchmarking are shown below:
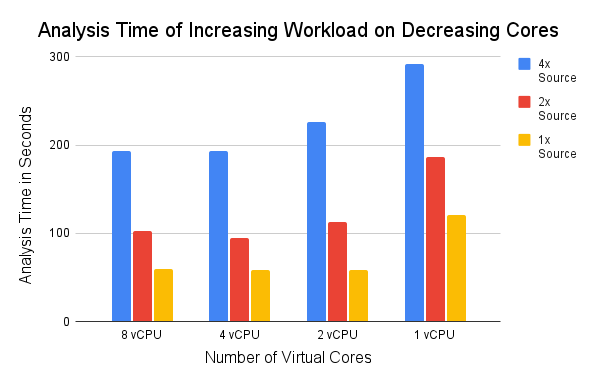
Figure: Analysis benchmarking of increasing number of files on various VM sizes.
We observe that only the difference between 1 core and 2 cores is substantial for all workload sizes while using 2, 4, or 8 cores performs similarly. It suggests that despite PMD’s per-file multi-threading, there is room for further improvements to parallelism.
PMD’s Scalability Concerns
In the previous section, we looked at scalability challenges and introduced some mechanisms PMD uses to split the workload. Now we will look a bit more into these mechanisms and the architectural decisions that improve and limit the scalability of PMD. Since PMD is a tool that a client will run locally via the command-line interface or a plugin, scalability in the sense of multiple users is not applicable. Concerning scalability, an ideal system should not have its response time affected by the workload, which is normally described as the number of clients or their number of concurrent requests6. Since PMD is not run on a server, the runtime is not dependent on the number of clients but on the resources of the system that PMD runs on. Therefore, we will focus on how PMD is currently dealing with the effect of the number and complexity of files on running time.
Current solutions
As mentioned in Key Scalability Challenges, every file must be parsed into an AST before the code can be analyzed. As you can imagine, this can take a lot of time if the number of files increases and the code itself becomes more complex. To do this more efficiently, PMD allows the user to increase the number of threads by using the --threads parameter78. By using multi-threading, PMD can share the resources across multiple tasks9. When multi-threading is enabled, an instance of a rule is not used by multiple threads concurrently, to ensure there are no threading issues10. Naturally, the number of threads and multi-threading performance are completely dependent on the system.
Furthermore, if a file is already analyzed before, it is a waste of time and resources to parse this file into an AST again. In order to prevent this and speed up the analysis, PMD can perform incremental analysis. The first time incremental analysis is performed, PMD will cache the results and analysis data, and store them in the location defined by the user. Then, the next time the user runs an analysis, PMD will only analyze the new or updated files. The results of the untouched files will be reused from the cache without parsing the file and executing the rules. As expected, reusing results improve the runtime of the analysis11 for both single- and multi-threaded runs, as can be seen in the figure below.

Figure: Results of a sample run with and without incremental analysis.
But how does PMD know if a file has been updated or if it can use the cached results? You want the exact same results as you would get without performing incremental analysis. PMD ensures this by saving the checksum of the file in the cache file, and the next time it looks up this file, it will compare the checksums. If the checksums are the same, we can use the cached results. If they are not the same, the cached results will be discarded, and the file will be re-analyzed. There are some other scenarios where the complete cache will be invalidated, for instance, when the new run uses another version of PMD or if it uses a different ruleset than before.
Besides parsing files into ASTs, traversing these trees while running the rules can be time-consuming. However, not all rules maintain states between visits, and for these rules, the order in which nodes in the AST are traversed is not important. PMD uses a mechanism called the rulechain10. By rulechain, PMD only passes relevant nodes to the rule instead of traversing through the whole tree. Another usage of the rulechain is running multiple rules on a single tree traversal12, which also improves the overall runtime.
Proposals of future improvements
We have seen that PMD has quite a few solutions for improving the runtime of the analysis, which is important in terms of scalability. However, the number of input files and the complexity are essentially limitless. Therefore, further increasing the tool’s scalability is always a good idea.
Proposal 1: Design A File Division Handler. PMD already uses multi-threading to analyze multiple files at the same time. However, it might still take time to explore a huge file. A solution for this could be dividing the single file into multiple parts and analyzing them concurrently.
Proposal 2: Cache AST Sections. PMD will re-analyze an entire file in the next run if the file is updated. This process also includes parsing the code into an AST and traversing it. Instead of completely discarding the cached result, we can reuse part of the results that correspond to part of the code that did not change. Then, we only have to analyze the changes and update the new changes in the cached result.
Proposal 3: Improve Rule Prioritization. PMD already prioritizes rules that do not have to traverse the whole tree. A small improvement to this prioritization of rules could be first executing the most common rules. The common rule violations will be found faster on average and therefore earlier presented to the user.
In Practice - Feasibility Check
In this section, we will plan our proposals more practically. However, it is worth looking at how PMD is preparing for its next release and how our proposals could fit in. The next major release of PMD is scheduled under version code 7.0.013. This version aims to tackle some technical debts, and especially, the highlighted goal is to separate the internal implementation from its well-defined, public APIs. The new annotation @InternalApi will be applied to such internal APIs. The diagrams below demonstrate how the changes will happen.

Figure: Current API design

Figure: Future API specification in PMD 7.0.0
We choose to follow the new internal and public APIs division to illustrate how our proposals are feasible and effective in PMD’s architecture. The file division handler in Proposal 1 should be an internal API, and this API allows PMD to automatically divide files into pieces without actually exposing this implementation to users. An additional supportive public API about the file division is also helpful. Users can decide whether they choose to use this file division unit with this public API, mainly when some users are concerned with the performance of their system to burden the additional operations induced by file division.
The cache implementation in Proposal 2 is somehow different than what we usually think. As PMD is an executable without its own memory, it needs to write to logs or binaries and uses such files as cache. So, it is better to categorize this function as an internal API because it requires the internal design of additional writing. PMD should also consider the overhead brought by this I/O operation in the new design. Similarly, an optional public API can be designed if users choose not to use this new mechanism. However, if the overhead is well controlled, PMD can also leave out this public API based on a minimalist principle (since this new API will not make any difference).
Proposal 3 requires a smarter rule prioritization algorithm, which should be placed in internal APIs. PMD developers can consider some rule-based prioritization ways to help improve PMD’s scalability.
Testing the Improvement - Validation Procedures
Here we also discuss an approach to test whether our proposals really help improve scalability after being designed in the new architecture of PMD. As local resources are the prominent dimension in PMD’s scalability issue, we can plot the response time and speedup with resources6 and then compare the two plots with the previous version of PMD to see whether the scalability indeed improves. Prior to the release, the PMD team should have an appropriate file to test the new functionalities. This file should have multiple separable components, which corresponds to Proposal 1. Later, following the idea of the alpha-beta test, it is also a good way to carry out a survey and gather users’ feedback through a beta version to see whether improvement indeed happens from the users’ side.
References
-
PMD Developers (2022). Merge pull request #3836 from JerritEic:issue3812-fix-TOC-many-headings. Retrieved March 24, 2022, from https://github.com/pmd/pmd/commit/59b36b6185e25f25b42c2781a25f81be749ce851 ↩︎
-
PMD Developers (2022). Java Rules. Retrieved March 24, 2022, from https://pmd.github.io/latest/pmd_rules_java.html ↩︎
-
Aleksey Kulikov (2020). Discovering the Most Popular and Most Used Github Actions. Retrieved March 24, 2022, from https://codecov.wordpress.com/2020/09/14/most-popular-and-used-github-actions/ ↩︎
-
GitHub, Inc (2022). About GitHub-hosted runners. Retrieved March 24, 2022, from https://docs.github.com/en/actions/using-github-hosted-runners/about-github-hosted-runners ↩︎
-
Microsoft (2022). Dv2 and DSv2-series. Retrieved March 24, 2022, from https://docs.microsoft.com/en-us/azure/virtual-machines/dv2-dsv2-series#dsv2-series ↩︎
-
Diomidis Spinellis. (2022). Architecting for Scalability (Lecture slides). Retrieved March 25, 2022, from https://se.ewi.tudelft.nl/delftswa/2022/slides/lecture4-architecting-for-scale.pdf ↩︎
-
PMD. (2018). How PMD Works. Retrieved March 25, 2022, from https://pmd.github.io/pmd-6.43.0/pmd_devdocs_how_pmd_works.html ↩︎
-
PMD. (2021). PMD CLI reference. Retrieved March 25, 2022, from https://pmd.github.io/pmd-6.43.0/pmd_userdocs_cli_reference.html ↩︎
-
Justin Stoltzfus. (2021). Multithreading. Retrieved March 25, 2022, from https://www.techopedia.com/definition/24297/multithreading-computer-architecture#:~:text=Multithreading%20is%20a%20CPU%20(central,of%20the%20same%20root%20process. ↩︎
-
PMD. (2020). Writing a custom rule - Economic traversal: the rulechain. Retrieved March 25, 2022, from https://pmd.github.io/latest/pmd_userdocs_extending_writing_java_rules.html#economic-traversal-the-rulechain ↩︎
-
PMD Developers. (2016). Incremental analysis #125. Retrieved March 25, 2022, from https://github.com/pmd/pmd/pull/125 ↩︎
-
PMD Developers. (2017). Document rule chain #597. Retrieved March 25, 2022, from https://github.com/pmd/pmd/issues/597 ↩︎
-
PMD. (2022). 7.0.0 development documentation. Retrieved March 25, 2022, from https://pmd.github.io/latest/pmd_next_major_development.html#new-logo ↩︎