From Vision to Architecture
Scrapy, as explained in our previous essay, is a framework that allows for easy, fast and custom web-crawling for a variety of tasks. More information about Scrapy can be found in the official documentation page.
Scrapy’s Architectural Style
Scrapy’s architectural style does not follow a single pattern, but rather extracts different characteristics from different architectural styles. Scrapy’s maintainer Adrían Chaves informed us that Scrapy was initially based on Django for the networking engine, but the team very soon decided to switch to - and still remains on - Twisted, a popular open-source, asynchronous and event-driven networking engine written in Python 1. An advantage of Twisted over Django is that Twisted allows Scrapy to respond simultaneously to different HTTP sessions due to its asynchronous nature. Twisted uses events to trigger communication between decoupled services, which in this context are the downloaders of different pages.
Additionally, Scrapy implements a Centralized architectural style meaning that a single or few entities have control over the entire system 2. In Scrapy’s case, the Engine acts as the “brain” of the system which is in charge of initiating and managing the communication and most of the data flow between all components.
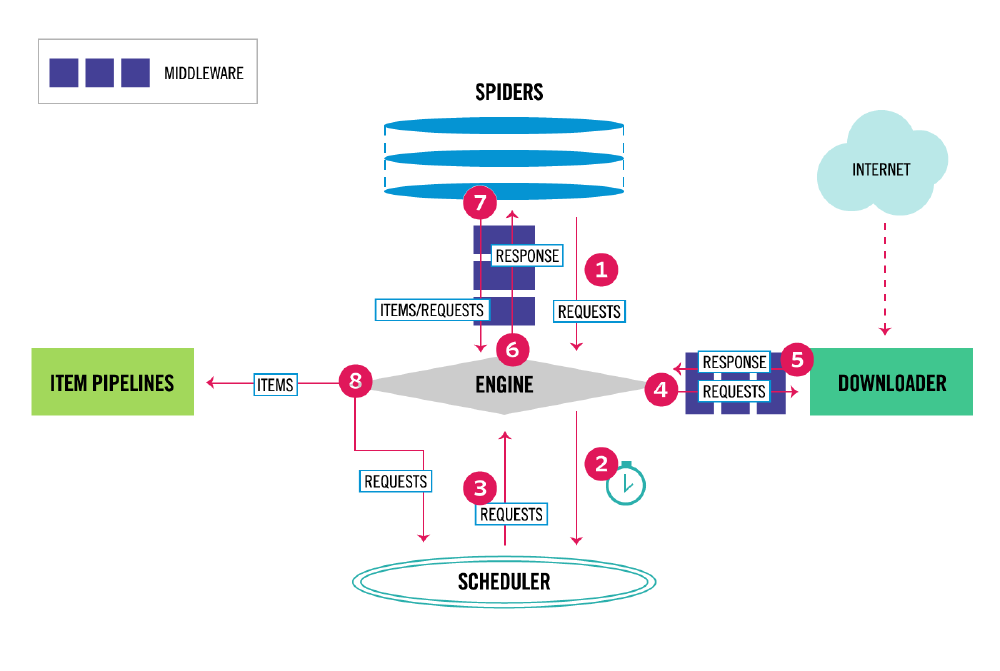
Figure: Scrapy’s Architecture, from [^5]
System Perspectives
To get a (near-)complete understanding of Scrapy’s system, we apply a set of different perspectives, since no single approach can encompass all of a system’s complexity 3.
Containers View
Software systems are often composed of one or more containers, representing separate execution environments that can be deployed independently 3. For instance, in a client-server architecture, the client application, the server application and the database of the system can be viewed as three different containers, which can be maintained and deployed independently of each other.
Scrapy is a standalone system composed of a single container employing multiple components which are connected together. The fact that all the components of Scrapy reside inside one big container can bring performance benefits, since crossing container boundaries may add latency 3, for instance network connection latency. The tradeoff of having a single container is that when it crashes, the components inside it crash as well, resulting in a complete failure. This is however not necessarily a problem, since detecting a complete system failure is often faster and can thus quickly be repaired, while partial failures can be harder to detect and its symptoms hard to debug 4.
Components View
Scrapy’s functional decomposition into its components is depicted in the figure above, which shows that Scrapy consists of the following elements, as explained in Scrapy’s Documentation 5:
- Engine: Controls the flow of data between all the system components.
- Receives items and requests from the spiders
- Sends items to the item pipeline
- Sends requests to the scheduler
- Receives the next request to be processed from the scheduler
- Receives the contents of websites from the downloader
- Sends the websites’ contents to spiders
- Scheduler: Keeps record of the priority of the requests
- Maintains a priority queue, either LIFO or FIFO, which may be persistent
- Enqueues received requests from the engine into the priority queue
- Provides the request that should be processed next to the engine
- Downloader: Downloads content of web pages
- Receives new request to be processed from the engine
- Downloads the webpage
- Sends the downloaded web page to the engine
- Spiders: Scrapes desired information
- Receives the downloaded web page from the engine
- Parses the desired information from the page into items
- Collects URLs from the page into new requests
- Sends the items and new requests to the engine
- Item Pipeline: Post-processes the items
- Receives items from engine
- Cleans up duplicates
- Stores items into database or locally
The core of the system is the Engine component. It is responsible for communicating with all the other components in the system. All the received requests, containing URLs, from the spiders are sent to the Scheduler, which provides the order of requests to be processed, using a FIFO or a LIFO queue, that can be persistent or not. The interaction between each component is done in an asynchronous —non-blocking— fashion, meaning that every component is working on their own task without being blocked or stalled by some other slower one 5. The Engine asynchronously “gives them a job” to do, and components reply with the result once the task is done. For example, a slow network connection would make the downloading of a page slow, and if the interaction between components was sequential or blocking then every job would eventually be delayed because of the slow connection.
Connectors View
The components, as discussed in the previous section, are connected through connectors. These connectors serve a variety of purposes and are not necessarily bidirectional. Connectors 3 can be method calls, using a queue as the shared data structure between components, a configuration in a file, etc. The components and the connections are depicted and numbered in the figure above. As can be observed, the engine is the component that is connected with all the other components, as it is the core of the application.
Most of the connectors between the components of the Scrapy system are method calls. Scrapy is event-driven, as previously mentioned, and it relies on the Twisted framework for asynchronous method calling. The Deferred object is employed in order to sequentially execute method calls on the completion of other methods that take significant amounts of time to complete, therefore impacting performance. For instance, the download method can be seen in Snippet 1. It starts downloading the web page and creates a Deferred object that will apply a chain of callback methods once the download has finished. This non-blocking aspect allows the method to continue running and return the same Deferred object to a different context from which it was called and apply other callback methods there as well. Scrapy relies on the flexibility of Twisted to mainly use asynchronous and non-blocking method calls.
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
Snippet 1: Deferred object in Downloader
Other types of connectors, which were not mentioned before, are the middleware components (e.g. spider middleware 6 ). They can be used as hooks between the different components in order to pre-process or post-process the message sent from one component to another. This is an interesting type of connector that relies on method calls to function.
Finally, other types of connectors can be remote calls to a database in for example the Item Pipeline component, in order to save the scraped results persistently.
Developer View
Scrapy’s codebase is composed of five main components, in order to group related code and functionality together, thus assisting in readability and maintainability of the project. The various internal and external dependencies of each component are depicted in the figure below.
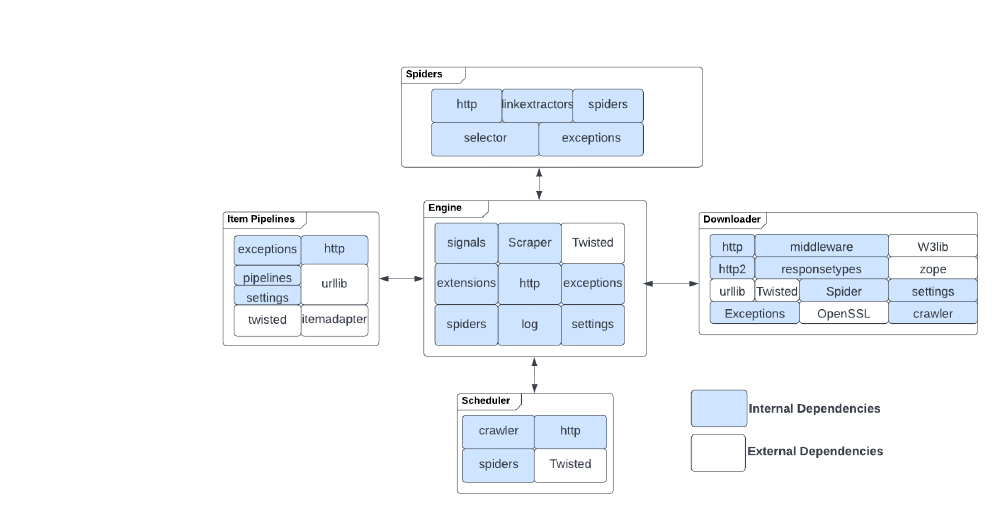
Figure: Internal and External Dependencies of each main Scrapy component
As one can see, Scrapy is dependent on multiple external libraries. The explanations and usage of these libraries are depicted in Table 1. Some of the libraries contained in Table 1 are not shown in the figure above since they are not a direct dependency of the shown components, but an indirect one through an internal dependency. An example of this is the spiders module that depends on the linkextractors module, which in turn depends on w3lib which is an external library containing various web functions.
| Dependency | Explanation | Usage |
|---|---|---|
| cryptography | Cryptographic algorithms, used to network level security | Security |
| cssselect | Parses CSS3 Selectors and converts them to XPath | Parsing |
| itemadapter | Wrapper for data container objects, providing a common interface to handle objects of different types in an uniform manner | Object Handling |
| itemloaders | Helps with collecting data from XML and HTML sources | Parsing |
| lxml | An efficient HTML and XML parser | Parsing |
| pyOpenSSL | Deals with network-level security needs | Security |
| parsel | An XML/HTML data extraction library that is written on top of lxml | Parsing |
| protego | Robots.txt parser | Parsing |
| queuelib | Persistent object collection | Storage |
| service-identity | Cryptography verification | Security |
| SetupTools | Facilitates packaging Python library projects | Packaging |
| tldextract | URL separation | Parsing |
| twisted | An asynchronous, event-driven networking engine | Networking |
| urllib | Used to bread the Uniform Resource Allocator (URL) strings up in components | Parsing |
| w3lib | Multi-purpose library of web related functions | Parsing |
| zope | Labeling objects as conforming to a given API or contract | Interfacing |
Table 1: External libraries that Scrapy depends on and their usage
Runtime View
Runtime View is the observed flow of function of a given system when it is run. From a user’s perspective, seeing as they are the ones running Scrapy, the flow of execution is rather straightforward. Namely, the user defines the parameters i.e. the webpage(s) to be crawled, the data that the crawler should gather, and the format the data should be stored as. In fact, when running Scrapy, the user only deals with the Spider. However, the components themselves act quite differently. To illustrate, a typical use-case presented by Scrapy’s documentation 5 goes as follows: A user makes a simple Spider whose job it is to collect quotes from a given webpage. Then the thread of execution begins:
- The spider sends the Engine the request, with the data to be crawled and the webpage(s) to crawl.
- The Engine schedules the freshly received requests in the Scheduler, and asks the Scheduler what requests it should work on now.
- The Scheduler hands over the Requests that should be currently worked on,
- The Engine sends the Requests to the Downloader.
- The Downloader, whose job it is to fetch and download webpages, sends back the downloaded page(s).
- The Engine receives these pages and hands them over to the Spider.
- The Spider does the essential task of properly crawling the downloaded pages for the needed data, and once finished, it sends back the crawled data along with the next Request to the Engine.
- The Engine gets the data and the possible next requests and hands over the data to the Item Pipeline. The Item Pipeline takes care of the format and storage of the data.
- This process is repeated until there are no more Requests.
Qualities and Trade-Offs
After having analyzed Scrapy from multiple views, we see that the system has achieved some key quality attributes through making some important trade-offs.
Key Quality Attributes Achieved
- Scrapy’s asynchronous, event-driven nature of the architecture allows for multiple jobs to be running simultaneously, so if one wants to perform a large-scale scrape, they can run the pipeline on a stronger machine that can handle more events 7.
- The decoupling of Scrapy’s components is useful when one wants to introduce some new behaviour to a component. This can easily be done by extending the Python class and implementing the required methods, while not having to worry about interaction between components.
- Finally the usage of Python comes with a lot of qualities, namely the ease of use of the library, cross-platform execution and the ease of developing a new Spider.
Trade-offs
- The usage of Python, although providing high ease of use, comes with a major tradeoff, which is speed, potentially restricting the usage of Scrapy from some enterprise level applications.
- The asynchronous style that is used might make a root-cause analysis of a given failure that occurred difficult 8.
- It can be difficult to deterministically unitest some spider, since the event-driven architecture of Twisted can potentially trigger undesirable responses 8.
API Design Principles
API design principles are conventions used to ease the implementation and use of APIs. Scrapy has a Core API with several sub-APIs, each customizable to the user’s needs. All APIs use interfaces that follow principles in interface design9. Scrapy’s API abides by the explicit interfaces principle, since it provides the user with the Crawler object which is the “main entry point to Scrapy API 10 .The few interfaces principle is fulfilled as well, seeing as Scrapy offers several different APIs and only offers one interface per API 10. Moreover, because each API specializes in a certain service, these interfaces fulfill the small interfaces principle by virtue of having few methods 10. Moreover, Scrapy’s API follows the principle of Consistency and Standards, because the usage of the API is unambiguous, thanks to the documentation provided and the uniform design across the different interfaces 1110 . The principle of Flexibility and Efficiency of Use is met as well, seeing as the interfaces allow customization at every step, meaning both beginners and experts can create an API fit to their needs.
Bibliography
-
Python Twisted Examples. (2012, September 1). Retrieved 10 March 2022, from https://wiki.python.org/moin/Twisted-Examples ↩︎
-
Bartoli, A., Dohler, M., Kountouris, A., & Barthel, D. (2015). Advanced security taxonomy for machine-to-machine (M2M) communications in 5G capillary networks. In Machine-to-machine (M2M) Communications (pp. 207-226). Woodhead Publishing. ↩︎
-
Pautasso, C. (2021). Software Architecture - Visual Lecture Notes (1st ed.). LeanPub. Retrieved from https://leanpub.com/software-architecture ↩︎
-
Lou, C., Huang, P., & Smith, S. (2020). Understanding, detecting and localizing partial failures in large system software. In 17th USENIX Symposium on Networked Systems Design and Implementation (NSDI 20) (pp. 559-574). ↩︎
-
Architecture overview — Scrapy 2.6.1 documentation. (2022, March 1). Retrieved 10 March 2022, from https://docs.scrapy.org/en/latest/topics/architecture.html ↩︎
-
Spider Middleware — Scrapy 2.6.1 documentation. (2022, March 9). Retrieved 12 March 2022, from https://docs.scrapy.org/en/latest/topics/spider-middleware.html ↩︎
-
Wikipedia. (2022, January 16). Event-driven architecture. Retrieved 11 March 2022, from https://en.wikipedia.org/wiki/Event-driven_architecture ↩︎
-
3Pillar Global. (2021, September 20). Disadvantages of Event-Driven Architecture. Retrieved 11 March 2022, from https://www.3pillarglobal.com/insights/disadvantages-of-event-driven-architecture/ ↩︎
-
Griffiths, J. (n.d.). The 5 Principles of User Interface Design. Retrieved 11 March 2022, from https://www.created.academy/resources/the-5-principles-of-user-interface-design/ ↩︎
-
Core API — Scrapy 2.6.1 documentation. (2022, March 1). Retrieved 10 March 2022, from https://docs.scrapy.org/en/latest/topics/api.html ↩︎
-
Mitra, R. (2017, December 19). Improve your API Design with 7 Guiding Principles. Retrieved 12 March 2022, from https://thenewstack.io/improve-api-design-7-guiding-principles/ ↩︎