Scalability
Scalability is a function of how performance is affected by changes in workload or in the resources allocated to run your architecture 1. There are various dimensions for Scalability: i.e Administrative, Functional, Geographical, Load, Generation and Heterogeneous scalability 2.
Since Scrapy is a single process library it can be shipped to each new user individually, and thus it is Administrative(ly) scalable. Additionally, since Scrapy’s design allows every component to be extensible, it is also Functionally scalable. Geographic, Generation and Heterogeneous Scalability will not be analysed due to time constraints, thus this Essay will focus on Scrapy’s Load Scalability: “the ability of a system to perform gracefully as the offered traffic increases” 3.
Load Scalability in Scrapy’s scenario means instructing Scrapy to crawl an increasing size of URLS, for example in a search engine / web indexing project, where each crawled URL has other URLs that Scrapy must follow later. In such web indexing cases, vast numbers of URLs per domain is not uncommon.
Benchmarking
The scenario mentioned was tested by creating a localhost server where Scrapy would perform HTTP requests to, and as soon as that request was fulfilled, Scrapy would add 20 new instances of that server’s URL to the URL queue. This simulates the outgoing URLs that an actual page would have. The results of this crawl are depicted in the figures below.

Figure: Memory Usage Benchmark

Figure: CPU Usage Benchmark
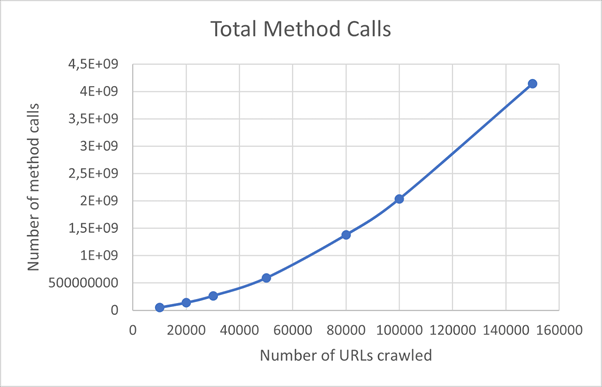
Figure: Method Calls Benchmark

Figure: Time Benchmark
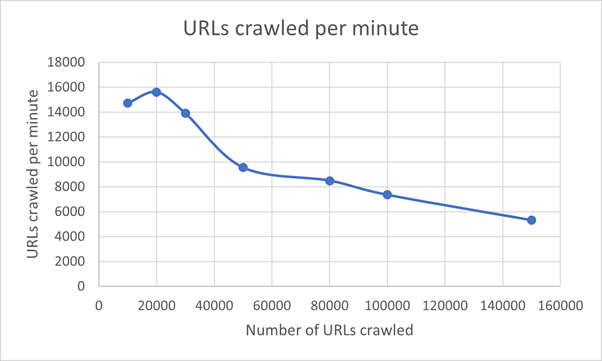
Figure: URLs Crawled Benchmark
We identified two key scalability issues from this analysis. The first issue is the high amount of memory that Scrapy requires to perform the crawls. For instance, when crawling 150.000 URLs, Scrapy used up to 2,17GB of RAM.
The second scalability weakness detected in this analysis was Scrapy’s CPU usage, which was very close to 100%. Since multiple other processes were also running in the background, such as the cProfiler, we believe that Scrapy attempts to utilize all of the processing power available to it. For example, Scrapy would use 100% of the single CPU core it was running on if there were no other processes running on it.
Last but not least, it is worth mentioning that the number of URLs crawled decreases drastically as the number of URLs to be crawled increases. For the purpose of benchmarking we used a localhost setting for the experiment. For this reason the number of URLs crawled per minute is quite high, as we do not have the network overhead. In a real setting, this number is expected to be lower, but the decreasing pattern is expected to occur in a similar fashion since all other factors remain similar.
Architectural changes
The main architectural decision that we identified that may affect scalability is the use of Twisted; the choice of single-threaded asynchronous programming instead of multiprocessing programming. This decision upper bounds the speed of Scrapy to a factor of the maximum processing power of (one of) the hosting systems’ CPUs.
Seeing that Scrapy runs on a single processor and reaches a constant CPU usage of (sometimes well over) 80% under heavy workload (as explained in the previous sections), it is expected that the CPU heats up and slows down the application. We propose a solution that involves running Scrapy over multiple processors in order to avoid a constant CPU usage above a certain threshold. Whenever the current processor usage passes the threshold, a spider will be spawned on another processor with an initial URL set, being a subset of the URL set of the “mother” spider. This spider spawning will be done similar to a Tree-like structure, where a node represents a spider and an edge a spawned spider offspring. Whenever the spiders are done scraping, they all send the processed items to the engine and the engine continues with the old workflow, adding the items to the items pipeline.
This approach allows for easier parallel crawling, at the cost of each spider producing their own output file and the user having to manually merge them into one.
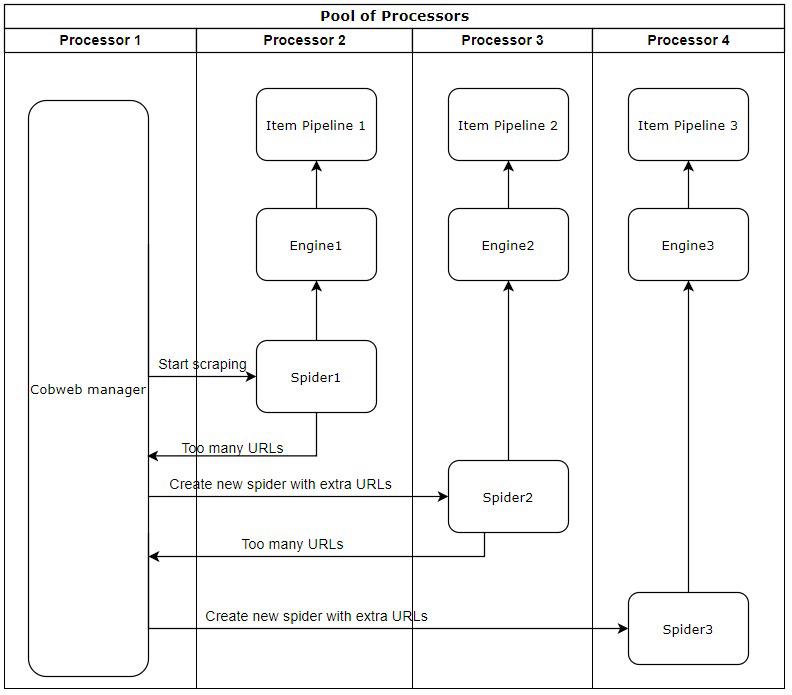
Figure: Cobweb Multiprocessing
Analysis of Multi-Processor Scrapy
The proposed solution to deal with Scrapy’s scalability issues, as discussed in the previous sections, is a big overhaul of the system, which makes a simulation or experiment infeasible due to time constraints. Instead, the proposed solution is reviewed analytically in comparison to the current system and it is discussed why the proposed solution indeed addresses the problems.
When Scrapy’s functionality was made in 2008, multithreading in Python was not as polished and frequently used. However, Scrapy’s functionality demands that different components, such as the Scheduler and the Downloader, are allowed to work at their own pace instead of waiting for each other. To enable this, Scrapy’s developers opted for an asynchronous approach between the components, making the Engine the leading component that receives asynchronous messages from the other components and organises the next steps. While this approach works well, as tested by the team’s studies of the system, it is limited by CPU usage when a spider has enough requests, as only one core is in use. Our team’s proposed solution to this is to employ multiprocessing, not within a spider itself, but rather in a “spider nest”, wherein multiple spiders run at the same time in different threads and possibly on different cores. This solution was proposed over multithreading within a spider because asynchronous messaging and multithreading cannot coexist. A rework of the whole spider would not only take a lot of time, but it would also potentially not provide any speed-up due to the shared memory nature of multithreading.
To critically analyse the proposed Cobweb solution, it is important to predict the actual speedup, and to analyse the solution’s drawbacks. As seen in the Time Benchmark Figure, a spider crawling 150.000 URLs takes approximately 1.700 seconds to complete. While this might not appear to be an issue within itself, when compared to the URLs Crawled Benchmark Figure, the throughput per minute when the same amount of URLs are called decreases significantly. For this reason, keeping the number of URLs low is beneficial.
Implementing our Cobweb solution, as depicted in the Cobweb Multiprocessing Figure, spawns a new spider at a certain threshold. To illustrate this through the above example, if the threshold would be set to 75.000 transactions, then 150.000 URLs would be completed in under 850 seconds. This small-scale example does however not indicate the full potential of our proposed solution.
Consider the hypothetical scenario where a user wants to retrieve 1 million transactions, and the threshold is set to 100.000 transactions. This scenario shows the true speedup of our proposed solution. Namely, per 100,000 transactions it takes Scrapy 800 seconds to retrieve all needed data. Applying linear regression to the function as depicted in
The Time Benchmark Figure provides a function in the form o y = m * x + b. Based on the data from this analysis, this equation becomes y = 0,00115 * x - 202,6558.

Figure: Gif of the Cobweb Tree-Structure
With 1,000,000 requests run on a single spider, it takes approximately 11.295,3 seconds, or a bit over 3 hours according to the regression function. Instead, our Cobweb solution with a threshold of 100.000 requests, with the spider creating a new instance which inherits half of the URLs and running them in parallel, the process would finish at worst case within 2.145 seconds. This speedup has been calculated with the deepcopy per 50.000 transactions per spider in mind, yet even with the overhead of copying transactions from one spider to another, the speedup factor is 5,26 x. The proper spider creation is shown in the animation above for ease of understanding.
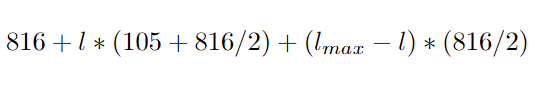
Figure: Speedup Formula
The above formula describes how to calculate the speedup, where l is the level of the node, lmax is the amount of levels in total, 105 is the amount of seconds needed to deepcopy 50.000 requests, 816 is the time in seconds needed to get to 100.000 requests, and 816/2 is the amount of time to process 50.000 requests, worst-case scenario.
Conclusion and discussion
Our analysis theoretically supports that multiprocessing, through multithreading, provides significant speedup, since threads are independent of each other and all run at their own pace 4. It is also worth mentioning that every spider produces its own baby spider once the threshold is reached, meaning no unnecessary spiders are created in this process. Finally, this solution has been made with race conditions in mind, i.e. situations where threads block each other when trying to access the same memory. Because each spider is its own fleshed-out instance of Scrapy, with the Cobweb only instantiating new spiders, there are no shared resources within these spiders, meaning no race conditions.
The choice to run completely separate instances, however, has its own drawbacks. Because all instances have their own Item Pipeline they all write to their individual files, the number of output files will be equal to the number of spiders instantiated. A proposed solution to this is to have the Cobweb contain a queue or superior Item Pipeline. This would however re-introduce the problem of race conditions, and due to the spiders running at different speeds, the blocking and waiting for the superior Item Pipeline to be free would outweigh the proposed speedup. Thus, our proposed solution would be to provide the user with a program that merges the output files into one or to let the user do it manually. The second drawback comes in the form of thread per core, namely multithreading can only lead to multiprocessing if different threads are allowed to run on different cores. To that extent, it is the user’s obligation to have multiple cores if they wish to obtain the presented speedup.
References
-
Pautasso, C. (2021). Software Architecture - Visual Lecture Notes (1st ed.). LeanPub. Retrieved from https://leanpub.com/software-architecture ↩︎
-
Wikipedia contributors. (2022, February 26). Scalability. Retrieved 25 March 2022, from https://en.wikipedia.org/wiki/Scalability ↩︎
-
Bondi, A. B. (2000, September). Characteristics of scalability and their impact on performance. In Proceedings of the 2nd international workshop on Software and performance (pp. 195-203). ↩︎
-
Beatteay, S. (2020, February 3). How to speed up your code with Multithreading. Retrieved 26 March 2022, from https://dev.to/sunnyb/how-to-speed-up-your-code-with-multithreading-3l5e ↩︎