The goal of Element is to provide a decentralized communication platform. This is achieved by using the Matrix protocol for exchanging messages. To recap from the previous essays: Element Web uses the Matrix client/server protocol to communicate with a Matrix server and the Matrix servers use the Matrix server/server protocol to communicate with each other. Therefore, two different points can be identified that influence scalability, the Element Web client and the Matrix servers. For the user, it is important that the Element Web client starts fast and shows events with a low delay. For providers that host a Matrix server, it is important that the server can process as many requests as possible.
Take for example a scenario in which a user has a lot of direct messages with people and is part of various active chatrooms. This means that the client-side receives a lot of events, and each event needs to be handled. An important concept that is used to keep the load for the client as low as possible is lazy loading. Only events that are currently of interest to a user are listened for. Also, only new events are synced at startup and older events are only retrieved when a user wants to see them. In this essay, we will first do a performance analysis. Then we will discuss scalability issues related to the communication between Matrix servers. Lastly, we will propose a solution to solve these issues.
Performance analysis
An interesting performance metric to consider for Element Web is the startup time of the application. At startup, information about users, chatroom members, messages, etc. need to be retrieved. The amount of data that needs to be retrieved can influence the startup time. In this performance analysis, the startup time is measured for different amounts of messages that are sent in the room displayed on startup. By measuring the startup time in relation to the number of messages, both the performance of the Element Web client and the Matrix server is considered. In addition, a fast or slow startup time is something that can influence the experience of end-users.
When a message is sent in a chatroom, this is modeled as an event.
The events that happened in a chatroom are retrieved at the end of the initialization phase of the application.
In the case of an encrypted chatroom, this is done through a call to the /rooms/<room_id>/messages endpoint of the matrix server.
This endpoint has a query parameter to limit the number of events returned.
Therefore, there are multiple calls made at the end.
To know the startup time of Element Web, the time it took from starting to load Element Web until the last /rooms/<room_id>/messages call is finished can be measured.
For this experiment, Element Web was deployed on a Cloud Run instance of Google Cloud Platform using the official docker image. The docker image 1 of March, 15th from Docker Hub was taken. The default configuration was used. It was deployed on an instance with 1 CPU unit and 128 MiB memory. Messages were sent in an encrypted room with no additional members. The message sent was “test”. For each amount of message, the experiments were repeated five times. Caching in the browser was turned off, such that all requests need to be made every time. In the table below, the average startup times are shown.
| Amount of messages | Time (s) |
|---|---|
| 1 | 3.584 |
| 10 | 3.682 |
| 50 | 5.804 |
| 100 | 6.512 |
| 200 | 6.448 |
It is clear that the startup time increases with the number of messages. Above a hundred messages, the startup time doesn’t increase anymore. This can be explained by the fact that Element Web only retrieves the latest 80 events. Additional messages are only loaded if a user scrolls up in the message history.
Another interesting performance analysis would be to test the impact of the number of users on the time it takes for a message to be received by all users. Additionally, it would be interesting to test the impact of the number of servers as well. However, both of these tests are difficult to do. For the first test, a lot of users need to be created and the registering process is hard to automate. For the second test, a lot of servers need to be deployed which requires a lot of computing resources.
Architectural scalability issues
Element envisions an E2E decentralized instant message platform. To achieve this they created the Matrix protocol, which is event driven (see figure below). This results in an decentralized system, which in most cases perform to standards. However, using this architectural decision there are a few cases where performance may suffer to scalability issues.
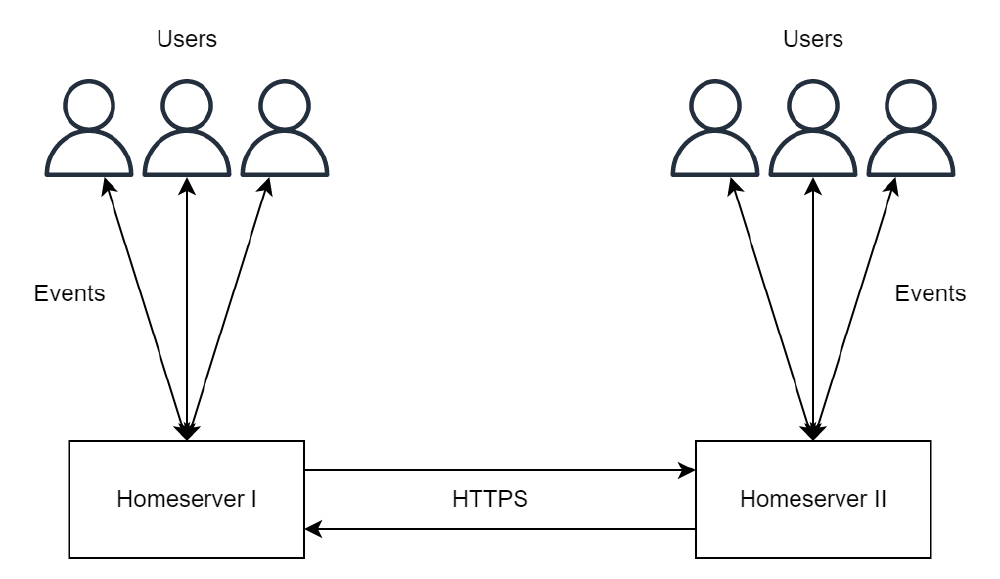
Figure: Matrix protocol
Many to one
As Element gets more popular, more people will experiment with this and create an account. It is likely, that most users will not pay for their own private server or host their own. This results in there being many clients connected to only one server. Not only might this result in the server being overloaded, but it also fails the goal of having a decentralized system. This is true since at that point there is only one server responsible for hosting all the data for all the users. Thus resulting in a normal centralized system with a single point of failure.

Figure: Many to one structure in Matrix
Many to many
There is of course also the opposite, where all users host their own homeserver. Due to the chosen architecture, this results in a many to many relation. Because the Matrix protocol is a decentralized protocol, all homeservers send messages to all other homeservers. That is why the protocol is called Matrix. Therefore, as more users host their own homeservers the message complexity increases. To be more specific: O(n²).

Figure: Many to many structure in Matrix
Architectural changes & tradeoffs
Therefore, one should ask the question if there are other possible architectures, which do not suffer from these scalability issues.
Many to one
The scalability issue in the many to one relation for homeservers with a huge number of clients, was already a known problem 2. One might argue that they should scale vertically by using faster server. This does not actually resolve the issue, since this solution does not scale well with an increasing number of users. Thus, one might argue to actually try scaling horizontally.
A way to solve this is creating smaller virtual homeservers inside the main homeserver when a certain number of active users have been reached. One would achieve this by putting users who share the same rooms in Element on the same virtual homeserver. This could be achieved by running for example a form of the k-means clustering algorithm. Then, when all users are divided, the virtual homeservers can use the same protocol used to exchange information between other servers to synchronize information. This way the user’s data is still stored on the same homeserver, but not one process is responsible for handling all events. The drawback here is that it might perform worse when not under load in comparison to the original architecture. However, this is a tradeoff one might have to make.
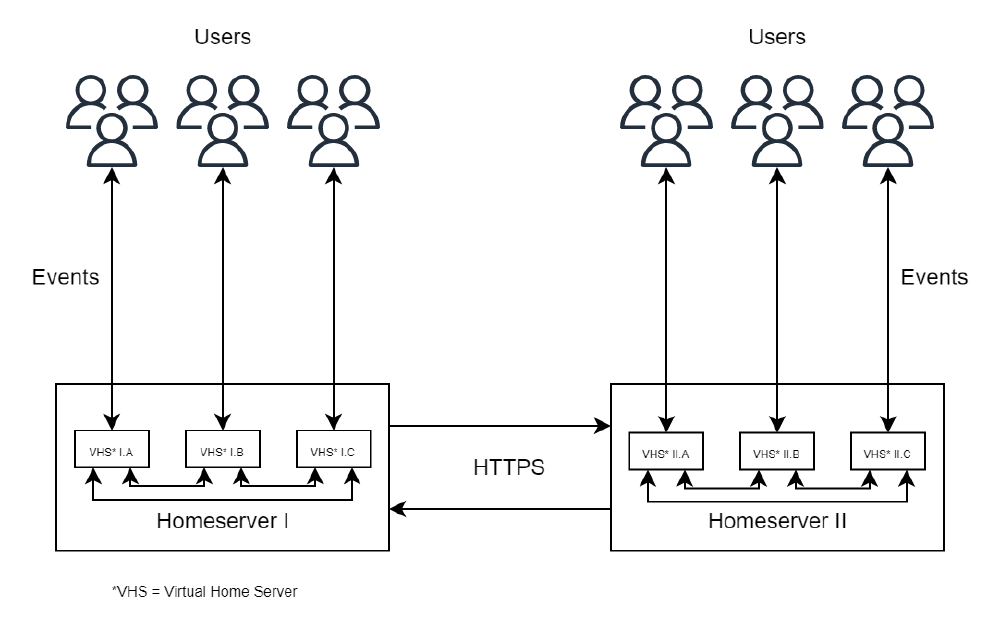
Figure: Matrix protocol
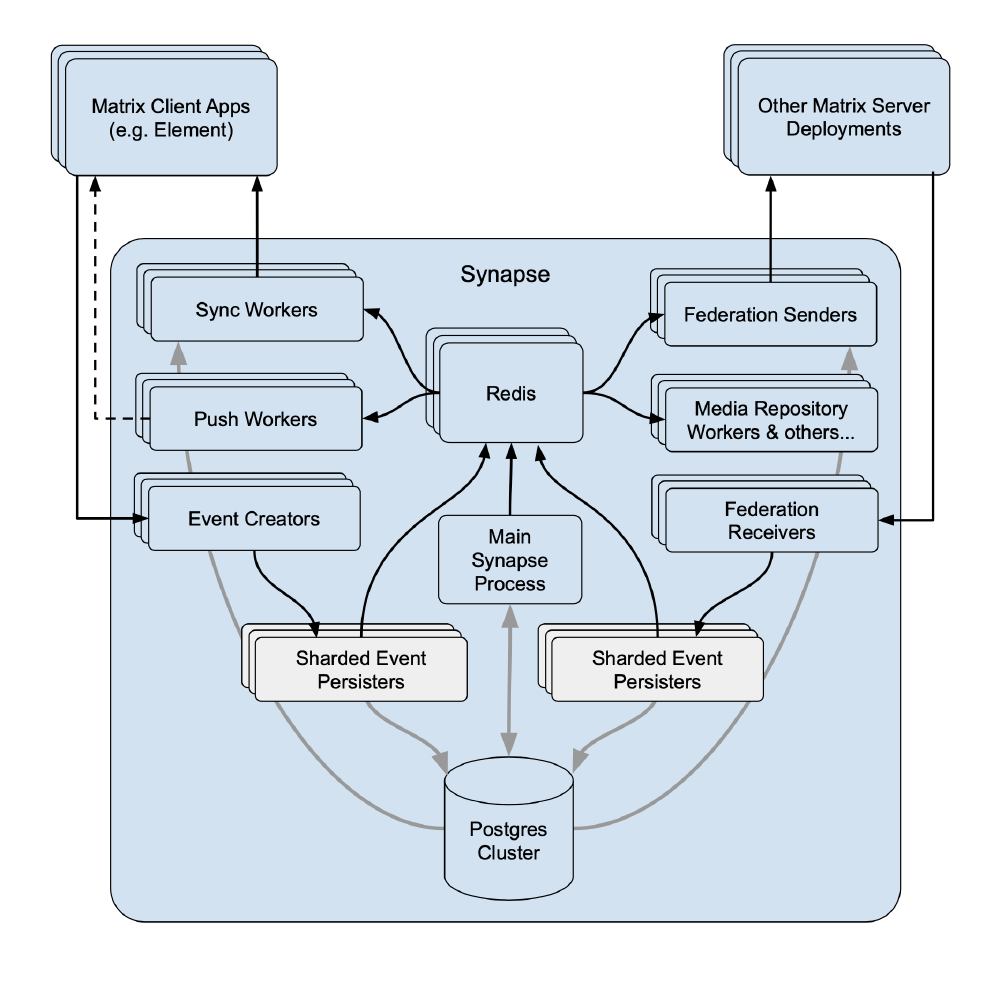
As already mentioned, the creators of the protocol were already aware of the problem and therefore recently came up with another solution. Instead of dividing the homeservers into multiple smaller virtual homeservers, they created a distributed algorithm that works with multiple processes. This results in that all events no longer pass through one single main process. Starting from a monolith server, they created a horizontally scalable server using micro-services.
Improvements were seen in the event sending time.
Messages being sent could take close to 1 second, but has been reduced to around 50 milliseconds.
Furthermore, the CPU usage has also been halved since the traffic has been split into multiple processors.
The major drawback of this system currently, is that the number of processes spawned is calculated on start up, with a restart required to changes the number of processes.
Thus, this system may not run optimally since there is an overhead of running a distributed algorithm, with there being less processes than needed at peak times and too many in other parts of the day.
For a more in depth explanation of these design choices, see their blog post about this 2.
Figure:
Horizontal scalable homeserver (source)
Many to many
A solution to the many to many solution is a more troublesome one. This is due to Element having the core vision of users being able to host their own data, as well as providing a secure platform. One might argue that not all servers would have to communicate with all other servers. However, doing this influences the security and reliability of the system. If a homeserver went down, this might mean that another server would not receive all new messages. Moreover, a server could go rogue and send invalid data to his neighbours. Therefore, this is a valid trade off between performance, scalability and reliability, security.
References
-
Element Web Docker Image. (2022, March 15). Docker Hub. Retrieved March 24, 2022, from https://hub.docker.com/r/vectorim/element-web ↩︎
-
Matrix.org. (2022, February 28). How we fixed Synapse’s scalability! Retrieved March 25, 2022, from https://matrix.org/blog/2020/11/03/how-we-fixed-synapses-scalability/ ↩︎