Scalability is a design concept that represents our vision of the future. “Even if a system is working reliably today, that doesn’t mean it will necessarily work reliably in the future”1. Therefore, when certain aspects change in the future, we hope that based on the existing architecture, developers can achieve a linear increase in overall system performance with only a few changes. Simply put, it is to adapt the current design to uncertain future changes. For Log4j2, although it is by far the best performing logging framework in Java, it still faces some scalability challenges. In this essay, we will briefly analyze the scalability challenges faced by Log4j2 and discuss how to improve the scalability of Log4j2 from the perspective of architectural design.
Key scalability challenges
Before we start discussing some specific issues, let’s first clarify the difference between performance challenges and scalability challenges,
- What is the performance challenge? If the system is slow to respond to a request, it is a performance issue.
- What is the scalability challenge? If the system responds quickly to a request but slows down as the number of requests grows, it is a scalability challenge.
After figuring out the definition of the scalability challenge, we need to succinctly describe what Log4j2 load is, and only then can we talk about growth (what happens if Log4j2 load doubles?). For Log4j2, we generally think of its load as logging requests per second, in addition to this, since Log4j2 offers an API for logging parameterized messages such as
logger.debug("Entry number: {} is {}", i, entry[i]);
So the number of parameters in the message can also be considered as a kind of load.
After understanding the load of Log4j2, now we briefly look at how to describe the system performance of Log4j2. Generally speaking, for batch processing applications, throughput is the key metric to describe their performance, and for applications that need to react to external events promptly such as a web server, they are more concerned with response time. However, since Log4j2 is used in both applications, both throughput and response time are important for Log4j2. Throughput is how many messages can be logged in a certain period, and response time is how long it takes to log a message.
Once we understand the load and performance metrics of Log4j2, we can investigate the scalability challenges: when the load grows in a particular way, what causes the performance of the system cannot handle the additional load well? We summarize two current Log4j2 scalability challenges:
- Asynchronous logger is not a panacea. Asynchronous logger does not handle location information and exceptions thrown during logging well2, and in addition, it does not improve performance in resource-constrained scenarios.
- Garbage-free is not all you need. The garbage-free mode of Log4j2 reduces the response time of logging by eliminating garbage collection pauses. However, the garbage-free mode reduces the throughput of Log4j2 and may not be as good as the classic mode in some application scenarios3.
Empirical quantitative analysis
In this section, to verify the scalability limitations of Log4j2 under different workloads, we conduct the experiments to analyze the impact of the number of parameters and the location information on asynchronous performance, and the trade-off between garbage-free mode and classic mode.
Our tests are built on Java Microbenchmark Harness (JMH)4 and refer to the performance tests in log4j-perf5. All tests were performed on
# Computer Info: Windows 10.0.19042, AMD Ryzen 7 5800H with Radeon Graphics, 16 GB RAM
# JMH version: 1.21
# VM version: JDK 11.0.12, Java HotSpot(TM) 64-Bit Server VM, 11.0.12+8-LTS-237
First, we want to analyze the throughput changes of AsyncAppender and AsyncLogger by changing the number of parameters contained in a message. We conducted the experiments on the cases of Thread=1 and Thread=4. Furthermore, we tested the effect of configuring with a location-related attribute includeLocation="true" on the throughput of both asynchronous methods. The experimental results are shown in the following figure.

Figure: The relationship between the increase of message parameters and the change of throughput
From the figure, we can see that as the number of parameters in the message increases, the throughput of AsyncAppender and AsyncLogger is significantly reduced whether it is Thread=1 or Thread=4. The impact of location information is very obvious in AsyncAppender, the throughput is reduced by around 6~7 times, and although the throughput of AsyncLogger is also reduced, the performance impact is not very large.
We also tested the effect of garbage-free mode and classic mode on the throughput of Log4j2, which can be achieved by setting Dlog4j2.enable.threadlocals={true/false} and Dlog4j2.enable.direct.encoders={true/false} to toggle. In this experiment, we use synchronous FileAppender to record logs, the experimental results are shown in the following figure.

Figure: A comparative experiment between the garbage-free mode and the classic mode
According to the figure, the system throughput of garbage-free mode is slightly worse than that of classic mode at different thread counts.
In general, Log4j2 cannot perfectly solve its scalability challenges so far so that it can cope with all scenarios. The increase of workloads such as message parameters will inevitably cause certain performance losses, and no garbage will reduce the response time. Causes a slight decrease in throughput.
System’s architectural decisions that affect its scalability
Powerful asynchronous logging capabilities are what sets Log4j2 apart from other logging frameworks.
Three improvements in the area of Asynchronous Logging allow Log4j2 to outperform Logback under high load conditions6. Firstly, it introduced Asynchronous Logger which can decouple the logging overhead from the thread executing functional code. And developers can choose between making all Loggers asynchronous or using a mixture of synchronous and asynchronous Loggers depending on their requirements on the best performance or more flexibility. The implementation of Asynchronous Logger is based on a lock-free inter-thread communication library – LMAX Disruptor library, resulting in higher throughput and lower latency. Log4j2 also proposes an alternative to Buffered File Appenders called Random Access File Appenders. The Random Access File Appender internally uses a ByteBuffer with RandomAccessFile instead of aBufferedOutputStream which increases performance by 20-200%6.
Besides, in the Log4j2 implementation design, a micro-kernel architecture is used, with a core implementing the requisite functions and a set of plugins for possible user-customized functions that are only added to the system when needed. This architectural decision offers the system expansibility, customizability, and flexibility. But when we analyzed the system, we discovered that plugin management may affect the system performance, like unnecessary plugins being loaded at startup and slowing down the system7. The plugin system and flexible configuration, on the other hand, increase the complexity of configuration and dependency and increase the system time overhead.
Proposed changes and their expected effects
Although the scalability of log4j2 has far surpassed other logging frameworks, we still put forward several suggestions in the hope that its speed can be further improved for a better user experience.
Standardized dependency injection API
The main problem occurs in the configuration and loading of the plugins. At present, the plugins are declared using annotation to the class declaration and the packages are declared in the XML file8. While this strategy has worked well for configurations where all necessary plugins are configured through the config file, this has left much duplicate functionality around log4j-core for loading other types of plugins9.
To better manage the plugins and clarify the relations, we propose that the dependency injection currently used in Log4j2 should be improved, unifying the loading and management of the plugins as a single mechanism. Dependency injection is a way of implementing the inversion of control. The inversion control transfers the control of objects and their dependencies from the main program to a third-party container or framework10, instead of having the program actively create and generate dependency on the target object. For our scenario, the inversion is about how they look up a plugin implementation11. The original architecture provides interfaces by grouping the plugins. For example, the Appender interface contains consoleAppender, DailyRollingFileAppender, FileAppender, RollingFileAppender.
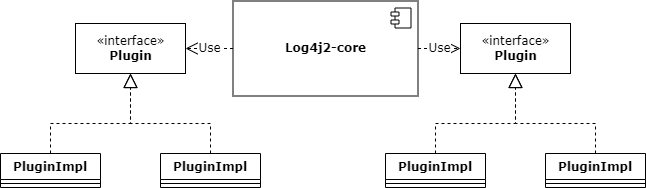
Figure: Log4j2 current plugin framework
Dependency injection separates the dependency from the program codes and the program wait for the dedicated mechanism to create and inject the dependencies into the program. This solution can help decouple the components and better manage the dependencies between each other. The use of annotations for configuration and XML files now used in Log4j2 is a primitive form of dependency injection. There are options using interfaces, constructors11, or a dedicated container12 that can realize the decoupling and dependency injection on a higher level. A dedicated dependency injection container creates an object of the specified class and also injects all the dependency objects through a constructor, a property or a method at run time12.
During our research, we found that there are already a similar proposal using dependency injection APIs for the future Log4j 3.013.
Binary Layout
The current logging system requires going from a LogEvent object to formatted text and then converting this text to bytes. According to LOG4J2-93014, formatting and encoding text is expensive and imposes performance limits. Converting logEvents directly to binary representation results in very compact log files that are fast to write. The cost of omitting text format is that binary logs cannot be easily read in a general-purpose editor such as Notepad. So we need a specialized decoding tool to convert binary files into human-readable form.

Figure: The plugin architecture after adding a PluginManager and BinaryLayoutBuilder
Conclusion
In summary, Log4j2’s scalability behavior is acceptable. Despite some performance issues, Log4j2 is still the best performing logging framework in Java and has been widely used by individual developers and enterprise applications.
In this essay, we tested the performance of Log4j2 under different workloads and identified the current scalability challenges. And we proposed several architectural optimizations on its plugin management and layout converter to improve its performance under the condition of more plugins and throughput demand. Log4j2’s Asynchronous logger and Garbage-free mode give it an edge over other logging libraries, and its diverse modules provide rich functions for users. However, in some scenarios, they can degrade the system’s performance. We need to mitigate these issues with better architectural design.
-
Martin Kleppmann. Designing data-intensive applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. O’Reilly Media, 2017. ↩︎
-
Apache Log4j2. Asynchronous Loggers for Low-Latency Logging: Trade-offs. Retrieved 27 March 2022 from: https://logging.apache.org/log4j/2.x/manual/async.html#Trade-offs ↩︎
-
Apache Log4j2. Garbage-free Steady State Logging: Performance. Retrieved 27 March 2022 from: https://logging.apache.org/log4j/2.x/manual/garbagefree.html#Performance ↩︎
-
OpenJDK. Java Microbenchmark Harness (JMH). Retrieved 27 March 2022 from: https://github.com/openjdk/jmh. ↩︎
-
Apache Log4j2. log4j-perf. Retrieved 27 March 2022 from: https://github.com/apache/logging-log4j2/tree/release-2.x/log4j-perf ↩︎
-
Apache Log4j2. Asynchronous Loggers for Low-Latency Logging. Retrieved 25 March 2022 from: https://logging.apache.org/log4j/log4j-2.3/manual/async.html ↩︎
-
Matt Sicke. Defer loading of StrLookup and PatternConverter plugin classes until first use. Retrieved 25 March 2022 from: https://issues.apache.org/jira/browse/LOG4J2-3441 ↩︎
-
Apache Log4j2. Plugins. Retrieved 25 March 2022 from: https://logging.apache.org/log4j/2.x/manual/plugins.html ↩︎
-
Matt Sicke. Dependency Injection and Configuration. Retrieved 25 March 2022 from: https://cwiki.apache.org/confluence/display/LOGGING/Dependency+Injection+and+Configuration ↩︎
-
Fatima Hasan. What is Inversion of Control?. Retrieved 25 March 2022 from: https://www.educative.io/edpresso/what-is-inversion-of-control ↩︎
-
Martin Fowler. Inversion of Control Containers and the Dependency Injection pattern. Retrieved 25 March 2022 from: https://martinfowler.com/articles/injection.html ↩︎
-
tutorialsteacher. IoC Container. Retrieved 125 March 2022 from: https://www.tutorialsteacher.com/ioc/ioc-container ↩︎
-
Matt Sicke. Create standardized scopes and dependency injection API. Retrieved 25 March 2022 from: https://issues.apache.org/jira/browse/LOG4J2-2803 ↩︎
-
Remko Popma. Improve PatternLayout performance. https://issues.apache.org/jira/browse/LOG4J2-930 ↩︎