In our previous blog posts, we analyzed the Moby project’s vision and architecture and its quality and evolution over the last decade. This time we will delve into an essential aspect of the modern software engineering world - scalability. In the world of Big Data and computers being omnipresent in the lives of billions of people, the ability to scale the developed solution and ensure its high availability became essential rather than optional. Docker’s widespread usage means that all of its characteristics affect thousands of systems worldwide and transitively - millions of end-users.
System’s key scalability challenges
Although containers are often portrayed as the Holy Grail of microservice architecture, they still have several limitations. We can distinguish two types of limitations, rooted in the environment in which Docker containers run or in Docker’s architectural decisions.
Operating system limitations
The majority of the limitations stem from the fact that containerized processes are still normal operating system processes at the end of the day, which just happen to be isolated from each other and the rest of the system. It means that they are still prone to the usual process limitations. Although these limitations were unlikely to be experienced by traditional applications, the ease of spinning up multiple containers makes it more common to hit the limits of the operating system.
Process thrashing
One of the examples is process thrashing. In case when there are too many processes performing CPU-intensive operations, it might lead to a situation where the kernel’s scheduler spends more time on context switching than actually providing the processes with the CPU time.
Parameter sharing
Another issue is that all the containers share the kernel and its parameters with the host operating system. While some of these parameters are namespaced and can be configured on a per-container basis, others are not. This means that they are shared by all the processes running on the machine, including the containerized ones. Examples include fs.file-max and vm.max_map_count, responsible for allocated file handles and processing the maximum number of memory map areas.
Port exhaustion
The simplicity of scheduling multiple workloads on one machine can also lead to port exhaustion 1 2. This problem occurs when processes on the machine use up all the ephemeral ports reserved for making outbound connections and are unable to establish new ones. In many cases, the containerized applications communicate with resources outside the host machine, like a web service or database server.
When the machine’s sole purpose is to run a single application, it is unlikely to exhaust the available ports. Techniques like request queues and connection pools allow keeping the number of used ports in check. However, these techniques are unsuitable when multiple heterogeneous containers reside on a single host. The amount of ephemeral ports also does not scale vertically as other resources do. Even if the host has enough memory and computational power to execute thousands of containerized processes simultaneously, it can still reach the limits of available outgoing connection ports.
Architecture design bottlenecks
In order to create the container, the Docker daemon often needs to pull missing image layers from a remote registry. Recent work has shown that pulling images can account for as much as 76% of the container start time 3. This is an issue since containers are often created dynamically in response to increased service demand. It often happens that the machines used to run the containers are provisioned dynamically as well, for example in the cloud provider’s data centers. This means they do not have the images cached locally and will have to pull them from the registry. It is crucial to have the starting process up and running as soon as possible in such cases.
Scalability-affecting architectural decisions
Limitations of the single host machine cause most of the containerization mentioned above issues. The simplest way to solve that is running containers on multiple machines instead, but that introduces a significant maintenance overhead. The solution to that problem is container orchestration, which revolves around treating multiple machines as a single logical unit called a cluster.
The most well-known container orchestrator in the market is Kubernetes 4, but Docker daemon has a built-in orchestrator mode as well, called Swarm 5. In the Swarm mode, the cluster nodes maintain the information about the desired state using the Raft consensus algorithm 6. It means that it is enough to issue administrative commands like the container deployment to a single manager node - it will replicate that information to other managers and proceed with deployment on the worker machines.
Container orchestration allows for horizontal scalability of the workloads by spreading them evenly among multiple machines. Not only does it prevent resource congestion, but also drastically reduces the chance of non-scalable bottlenecks like port exhaustion happening.
It also allows for assigning dedicated cluster machines for specific workloads, preventing other applications from being scheduled on them. This allows for tweaking the non-namespaced kernel parameters specifically for the applications scheduled to run on these machines.
Architectural decisions negatively influencing scalability (about Docker registry)
The reference implementation of the Docker image registry revolves around stateless service, which provides a REST API and serves the images from the underlying storage where the image layers are stored.
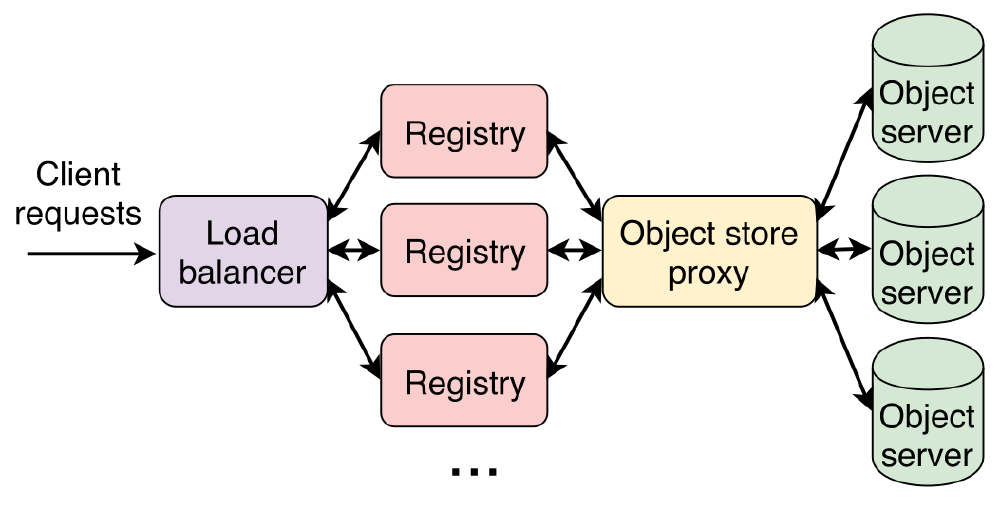
Figure: Common Docker image registry deployment model (source).
When an image is requested from the registry, its manifest 7 is pulled first. This contains references to the layers that build up the image. Missing layers will be requested by Docker and downloaded from the registry. Pushing images to the registry consists of the same steps as before but in reverse. First, the missing layers are pushed to the registry, and finally, the manifest is added.
Although the stateless design of the registry technically allows for horizontal scalability, there is a significant drawback. The default implementation doesn’t utilize the potential of Docker’s image structure, caching only the layer metadata but not the layers themselves. Even if the layers were cached, the load balancer in front of the registries would have no information about what node is caching what layers. This results in redundancy and wasted storage on the registry nodes.
In the current design, under heavy load, the main bottleneck is load balancing. Because the load balancer is responsible for forwarding the request to the registries, a large number of clients will saturate the network.
Last but not least, the most commonly used deployment approach introduces multiple hops to process every request: communicating with the registry load balancer, proxying the request to one of the registry nodes, requesting data from the persistent storage middleware and finally, finally fetching the actual layer data. These points combined result in high latencies and poor scalability of the registry system.
Proposed solution
Related to the limitations given the containerized context, we propose a solution focussing on scalability in setting up new containers. The solution focuses on the architectural design which connects moby to the registries pulling different layers of the images. A vast part of the issues related to registry services mentioned in earlier sections was solved, as we can see by the updated design proposed by Littley et al., which uses a hyper-converged design. The new design, named Bolt, uses a hyper-converged design 8 to overcome the problems of the existing registry design, as opposed to the traditional designed registry services, which require multiple loosely connected servers. In a hyper-converged infrastructure, individual machines combine multiple logical roles. For Bolt, this means that the individual registry nodes store data locally, eliminating the need for a separate storage backend.

Figure: Bolt hyper-converged design (source).
Instead of a central registry, the clients get a list of the available registries from any node. Consistent hashing is used to enable the clients to determine at which registry nodes the layers are located. This is facilitated by the highly reliable distributed coordination application Apache Zookeeper. After determining this, the client pulls the layers from the nodes directly - this way, the load balancing is done by the client. Moreover, layers are stored over multiple nodes in a highly available fashion to ensure reliability. The client uses the hashing to determine the master node. Once the master node receives the layer, it forwards it to its followers. One final point worth mentioning is that Bolt allows for the dynamic addition and removal of registry nodes from existing setups, allowing easy registry deployment scaling.
Solution analysis
The proposed solution was compared to the conventional distributed registry by re-playing production traces from an IBM registry containing around 0.26 Million requests in total 9. The performance of both systems, the conventional one, and Bolt, was compared by increasing the number of clients connecting to the registry. As shown in the figure below, Bolt outperforms the conventional registry design significantly and improves latency by order of magnitude and throughput by up to 5 times. According to the authors, this performance improvement can be explained by the caching of layers in the Bolt architecture. Moreover, in the Bolt design, only one hop is required to request the layer, whereas, within the conventional registry design, a multitude of hops is required.

Figure: Latency and throughput dependency on clients number.
The scalability was evaluated by increasing the number of registry instances from 1 to 10 and measuring the request throughput and latency on the clients’ side. As can be seen in the figure below, adding instances caused a linear increase in throughput, together with an almost linear decrease in latency. When it comes to fault tolerance, as shown in the figure below, after killing one of the five registries, the ephemeral Znode exists three seconds later, which causes the client’s requests to fail. However, once the registries update their rings, requests stop from failing. Moreover, after the node is brought back up, the rest of the nodes become aware of it within milliseconds, allowing the throughput to recover to typical values.
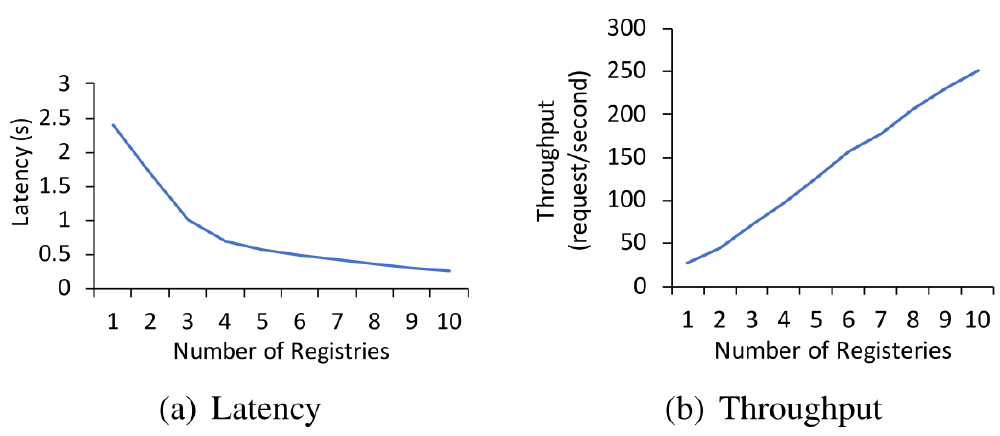
Figure: Throughput and latency for increasing number of registry nodes (source).

Figure: Throughput with and without failure of a registry node (source).
Conclusion
In this essay, we looked into the scalability of Docker containers and the limitations imposed by the nature of containerization. We also looked into how container orchestration solved these limitations in a way that doesn’t introduce a considerable maintenance overhead.
By broadening our search scope, we performed an in-depth analysis of the Moby project. We identified an issue with the reference implementation of the image registry, which limits its horizontal scalability. We also found and analyzed the solution, aiming to treat the registry stack as a distributed system that makes better use of container image characteristics and avoids bottlenecks present in the most common deployment strategy.
It is clear that the key quality attributes of the Moby project play a significant role in its development. Thanks to the use of standardized protocols like REST, it was possible to develop a solution for unforeseen bottlenecks. Although Bolt uses a different architecture than its reference counterpart, it is still fully compatible with the vanilla implementation, paying tribute to the project’s modular design. Bolt’s improved design provides a significant performance increase, escalated throughput, and minimal latency, which are very valuable in large image registry deployments.
-
https://docs.appdynamics.com/21.7/en/infrastructure-visibility/network-visibility/workflows-and-example-use-cases/tcp-port-exhaustion-example-use-case ↩︎
-
https://making.pusher.com/ephemeral-port-exhaustion-and-how-to-avoid-it/ ↩︎
-
HARTER, T., SALMON, B., LIU, R., ARPACI-DUSSEAU, A. C., AND ARPACI-DUSSEAU, R. H. Slacker: Fast distribution with lazy docker containers. In 14th USENIX Conference on File and Storage Technologies (FAST 16) (Santa Clara, CA, 2016), USENIX Association, pp. 181–195. ↩︎
-
https://www.actualtechmedia.com/wp-content/uploads/2018/04/SCALE-The-Fundamentals-of-Hyperconverged-Infrastructure-v2018.pdf ↩︎