The main architectural style
In PMD - Product Vision, we focused on the vision and context of the PMD project. In this essay, we will focus on a high-level view of the architecture of the system. The main architecture pattern is the pipe and filter pattern1, and the concrete overviews of architectural views are given:
- The main architectural style
- Container View
- Component and Connector Views
- Development View
- Runtime View
- Key Quality Attributes and Trade-offs
- API Design Principles
- Conclusion
- References
According to the workflow documentation of PMD2, the main pattern applied is the pipe and filter pattern1, which has main entities called filters. Filters perform transformations on the data and process the input they receive. After the current filter is done, the data goes to the next filter. In the case of PMD, the ‘Data Source’ are the files PMD has to analyze. The three major filters in PMD are:
- First filter: The source files with the same language (e.g. Java, Apex, XML) will go through the same filter in the next level.
- Second filter: The parser will parse the source code into root AST node.
- Third filter: Consists of rules to analyze the source code, by traversing the AST and reporting found problems as
RuleViolations.
Figure: Data transformation in a pipe and filter architecture
There are some advantages of this pattern. First, each filter can run concurrently and independently. Furthermore, filters offer flexibility, which means that they can be changed without modifications to other filters. Besides, filters can be treated as black boxes: users of the system can run PMD without knowing the logic behind each filter. Lastly, filters offer re-usability, which means that each filter can be called and used repeatedly. However, this pattern also comes with a disadvantage: users cannot interact with PMD while it is running.
Container View
For the breakdown of the system architecture, we start from the broad container view. In the C4 Model3, a container is some self-contained part that must be present in order for the overall software system to work. Following this description, we identify containers based on how PMD operates in several execution environments. In PMD, we have End-users, Command line interface, External IDE, PMD-Core, Languages, Input Files, and RuleSets.
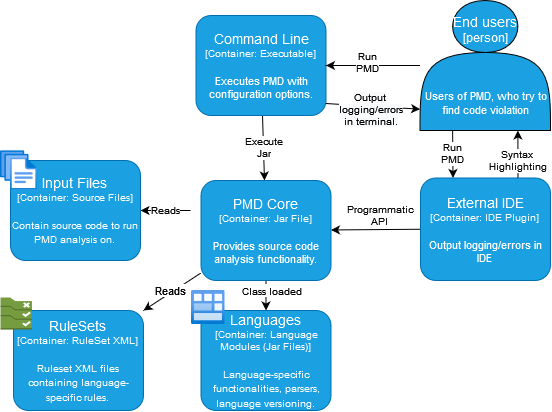
Figure: Container View
Component and Connector Views
PMD’s container design is modular, placing both
Figure:
Component and Connector View
Language modules and RuleSets as external dependencies. This has the advantage of keeping the main container PMD-Core, less complex, easier to develop, and easily extensible. To provide a more detailed explanation of the PMD-Core container, we decompose it into a set of components with interlinking connectors, based on the C4 Model3. The resulting diagram is shown below:

In this component and connector view, we depict seven important components of the PMD-Core container, explaining how they interact during a typical execution of PMD. For the purposes of this diagram, we assume that the user has configured PMD to operate through a command line interface (instead of its programmatic API for use in continuous integration or an IDE plugin). Thus, the user has provided a set of Input Files, some additional RuleSets, and run PMD with a set of options. Upon execution, a PMDConfiguration class is instantiated with the user-provided options. Then, the PMDAnalysis class uses the configuration options to load the selected RuleSets from file into a list. Based on the loaded rules, PMDAnalysis determines all of the relevant languages and requests the related Language module to be loaded with the Java ServiceLoader class4. After this, PMDAnalysis instantiates a Rule Checker runnable class for each input file, which perform the actual rule checking in a multi-threaded scheme. Each Rule Checker gathers the relevant RuleSets for the file it is analyzing, then the relevant languages for those RuleSets. Each Language module has a related Parser that leverages either JavaCC5 or ANTLR6 parsing to transform input text into an abstract syntax tree (AST)7. The Rule Checker for each files uses this Parser on the source code, which is loaded from file. Once the Parser has created the AST, the Rule Checker performs a check of each rule against the AST. The results of each rule from each Rule Checker are passed to Report classes, which aggregate the rule results from all files before PMDAnalysis writes these results as formatted text back to the command line.
Each of these components is interlinked with some combination of other components and containers, thus we extend the component view with an additional analysis of connectors. Within the PMD-Core container, most connectors are in the form of method calls, based on the well-established principles of Java Class APIs. The use of modularization via Java Classes is a tried and true approach to system design, and it has many advantages: since Java is a statically and strongly typed languages and these classes exist within the same compilation unit, many potential API incompatibilities are caught before runtime as compilation errors. Similarly, new functionalities can be easily implemented as inheriting classes, reusing existing API designs8. However, insufficient separation of public and internal APIs can cause technical debt to build up over time: this is the reasoning the PMD developers gave behind needing to remake the PMD API for PMD’s next major version9.
Connectors to external containers include multiple file reading connections for Input Files and RuleSets, as well as writing to the Command Line. A particularly interesting connector however, is the use of the java ServiceLoader class4 to load in necessary Language modules at runtime. Once loaded, the languages can be accessed as normal by other classes. This design decisions decouples the PMD-Core and Language containers, allowing development of new Language support entirely separately from the PMD-Core.
Development View
In the previous sections we have shown a high-level overview of the structure of PMD, and now we will discuss the development view. The development view is one of the four essential views in the architectural model described by Kruchten10. It is described as “the static organization of the software in its development environment”10. The stakeholders in this view are the programmers and software project managers. In this section the development view of PMD will be discussed. The PMD repository can be divided in three main categories: documentation, source code, and tests.
Documentation
In the docs directory the documentation of the current version of PMD is written. It is constructed as a regular webpage, generated by the static sitegenerator Jekyll. Therefore, documentation can be written in simple Markdown files.
Source code
As mentioned in Component and Connector Views, PMD consists of Language modules for the many supported languages, and the main container PMD-Core.
In the PMD-Core directory the main functionalities of the tool are implemented. Among other classes, PMD.java, which is the main entry point for the command line interface, and PmdAnalysis.java, which is the main programmatic API, can be found here. Furthermore, the source code parser, report generator, and all components of the rule checker are implemented in this directory as well.
In the Language modules the language specific parsers are implemented. Furthermore, rules, metrics, and other language specific functionalities can be found here as well.
Tests
For PMD-Core and each Language module there are individual test directories. In this way the tests are not cluttered and only targeted to the corresponding module.
Runtime View
Thus far we have seen an overview of the architecture of PMD, and how it is developed. Let’s now take a look at what actually happens when a user runs PMD. As mentioned before, there are many ways to make use of PMD, for example via Maven, Gradle, or an IDE like IntelliJ or Eclipse. In this section the runtime view of PMD in the command line interface will be described2.
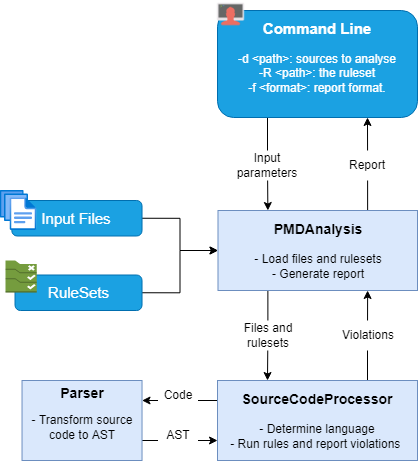
Figure: High-level runtime view of PMD
Upon execution PMD parses the command line parameters provided by the user. Based on these parameters, it loads the corresponding RuleSets and rules in PmdAnalysis. Subsequently, it determines the files it has to analyze, using the given source directory, and the corresponding languages, based on the RuleSets. With this configuration, PMD prepares and calls the SourceCodeProcessor, which analyzes the files using the rules as follows:
- Determine the language of the file using the
determineLanguagemethod. - Check if the file can be skipped, if a result is already available from the analysis cache.
- Transform the source code to an abstract syntax tree (AST) using the (language-specific)
Parser. - Build scopes, and find usages and declarations using the
SymbolFacadevisitor. - Build control flow graphs and data flow nodes using the
DFA(DataFlowAnalysis) visitor. - Find the types of the classes using the
TypeResolutionvisitor. - Run the rules that do not maintain states between visits. For these rules the order in which the nodes in the AST are traversed is not important.
- Run the other rules by traversing the constructed AST, while making use of the information obtained from the
SymbolFacade,DFA, andTypeResolutionvisitors.
After the SourceCodeProcessor is done with the analysis of all the files, PMD generates a report of the found violations in the format desired by the user.
Key Quality Attributes and Trade-offs
In this section we will discuss how PMD’s architecture realizes key quality attributes, and the potential trade-offs.
Modularity is a consistent quality attribute in different views of PMD’s architecture2. In its container, component and connector views, PMD is naturally modularized to regulate different running parts for its functionality. Also, in its development view, modularity ensures PMD to easily extend its PMD-Core to different languages; in the runtime view, modularity enables PMD to quickly locate the implementation of a certain language and run corresponding parts of code. Other quality attributes are reflected in certain parts of PMD. For example, flexibility is empowered by PMD’s RuleSets, where a subset of rules will be applied to the run-time instance of PMD. Testability is ensured by PMD Tester11, which is provided to developers for the improvement of PMD.
A potential trade-off, induced by modularity, is extensibility versus integrity. PMD is inclined to integrity since it uses a universal command line interface for its supported languages. It implies that if PMD plans to support new command line arguments for its code analysis, it needs to implement the arguments for all its languages, which sacrifices extensibility for an only, specific language. Other trade-offs include flexibility versus maintainability, where PMD exploits its RuleSets to manage the flexible inputs, and portability versus feasibility, where PMD extends its service to all common operating systems, and so forth.
API Design Principles
PMD sets its own API guidelines9 for its consideration in, for example, simplicity, consistency and information hiding. We emphasize the simplicity of PMD’s API design based on its command line interface, which provides simple but powerful functions with its command line arguments. PMD also continuously refines its naming and deprecates some APIs to ensure consistency and minimize redundancy. As PMD gradually opens all its public members and types to users, it also strives to hide some methods and constructors and avoid users’ access to them.
Specially, PMD defines some “rule rules” to guide its future contributors to write appropriate PMD rules12, which constitute an important part of PMD’s API structures. Some do’s and don’ts are clearly specified and they reflect various principles, such as “Don’t put the implementation of the rule in the name” (easy to maintain code), “Don’t limit the rule name to strictly what the rule can do today” (easy to extend), and “Do write rule messages that neutrally point out a problem or construct that should be reviewed” (hard to misuse).
Conclusion
PMD is a highly modularized static code analysis tool with a well-ordered workflow in different views. In this essay, we walked through PMD’s container, connector, component and code views with further details in PMD’s development, runtime, quality trade-offs and APIs. We hope you enjoyed this essay and learned about PMD’s architecture in a comprehensive manner.
References
-
Syed Hasan. (2019). Pipe and Filter Architecture. Retrieved March 10, 2022, from https://syedhasan010.medium.com/pipe-and-filter-architecture-bd7babdb908 ↩︎
-
PMD. (2022). How PMD Works. Retrieved March 10, 2022, from https://pmd.github.io/latest/pmd_devdocs_how_pmd_works.html ↩︎
-
Simon Brown. The C4 model for visualising software architecture. Retrieved March 12, 2022, from https://c4model.com/ ↩︎
-
Oracle. (2021). ServiceLoader. Retrieved March 12, 2022, from https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/ServiceLoader.html ↩︎
-
JavaCC Community. (2022). JavaCC. Retrieved March 12, 2022, from https://javacc.github.io/javacc/ ↩︎
-
Terence Parr. (2022). ANTLR. Retrieved March 12, 2022, from https://www.antlr.org/ ↩︎
-
Wikipedia Contributors. (2022). Abstract syntax tree. Retrieved March 12, 2022, from https://en.wikipedia.org/wiki/Abstract_syntax_tree ↩︎
-
BJ Hargrave. (2018). API design practices for Java. Retrieved March 12, 2022, from https://developer.ibm.com/articles/api-design-practices-for-java/ ↩︎
-
PMD Developers. (2022). PMD 7.0.0 development. Retrieved March 12, 2022, from https://pmd.github.io/latest/pmd_next_major_development.html ↩︎
-
P.B. Kruchten. (1995). Architectural Blueprints—The “4+1” View Model of Software Architecture. Retrieved March 12, 2022, from doi: 10.1109/52.469759. ↩︎
-
PMD. (2022). Pmdtester. Retrieved March 13, 2022, from https://pmd.github.io/latest/pmd_devdocs_pmdtester.html ↩︎
-
PMD. (2022). Guidelines for standard rules. Retrieved March 13, 2022, from https://pmd.github.io/latest/pmd_devdocs_major_rule_guidelines.html ↩︎