Introduction
Scalability is an important quality attribute for many software projects, sometimes it can even be a direct prerequisite for success. With this in mind, what does scalability mean for the Quod Libet project?
Unlike some, Quod Libet will scale to libraries with tens of thousands of songs. 1
Quod Libet markets itself on its scalability, specifically promoting its suitability for massive music collections. It makes sense for us to evaluate Quod Libet’s scalability along the same axis it evaluates itself, so this article will focus primarily on how the program scales to very large music collections. First, we will examine some of the key challenges standing in the way of this type of scalability. Next, we will measure how well the current version Quod Libet overcame this challenges. Finally, we will look at how Quod Libet achieves the performance it does, and what could be changed to further improve performance.
Key scalability challenges
Based on one study from 2011, the average iTunes user has 7160. Competitor apps like Spotify allow their user to have 10 thousand songs for in each playlist, while Apple Music allows a maximum of 100 thousand songs in a library 2. Based on these findings, we can conclude that a use case of 100s of thousands or even millions of songs is plausible.
As a music collection grows, the performance challenges inherent to working with it accumulate. Different scales introduce their own challenges, which place requirements on the architecture. To test the scalability of Quod Libet, we imported a range of files into the Quod Libet library and measured the performance.
As a music collection grows, the performance challenges inherent to working with it accumulate. Different scales introduce their own challenges, which place requirements on the architecture.
1,000 Songs
Audio data can no longer fit in RAM Even music collections as small as 1,000 songs can take up gigabytes of space. At this point, the program should avoid loading every song at once. Instead, audio data needs to be loaded from storage on demand.
10,000 Songs
UI Components can’t be created for every song By this point, instantiating a UI component to represent each song would begin to slow down the interface. The user would experience this as latency and stuttering when scrolling through their music collection. To avoid this, the program must apply the partial representation techniques discussed later in this essay.
100,000 Songs
Super-linear operations become expensive By the time a collection contains 100,000 songs or more, tasks more complex than O(n) will become problematic. For example, sorting songs in alphabetical order may have a noticeable delay. These expensive tasks should be avoided if possible, otherwise they should be decoupled from the UI so that they don’t cause the interface to freeze.
1,000,000 Songs
Song index may no longer fit in RAM Quod Libet uses Song objects which point to files, but about 1 million elements the collection of song objects itself may become impractically large. Beyond this point, the program needs to rely more on the filesystem, and care should be taken to only work with subsets of the total list whenever possible.
Slow linear operations become expensive Quod Libet provides a regex search utility. If the regex pattern is moderately complex, matching may take a non-trivial amount of time. Matching against every song in a 1 million song collection can become a very expensive task, despite its O(n) complexity. To ameliorate this, the program may need to introduce multithreading and perhaps even perform searches asynchronously.
Quantitative Analysis
Different configurations were tested to quantitatively assess the scalability of Quod Libet. The performance of Quod Libet is affected by the number of song files Quod Libet needs to load.
Startup Time
Quantitative analysis on startup time is performed via the cProfile tool. This resulted in detecting the increase of time in the functions of the qltk/chooser.py file which control the File System widget, and are called when folders are scanned. As the interaction via the OS File System API occurs via the GTK library, increases in time are also to be found in the log in the calls to the GTK library functions (Gtk.py) which also account for the wait caused by the system calls, some of which occur via C built-in modules. The numbers here yielded measure the time required for Quod Libet to both fully start and read the amount of files involved in the experiment.
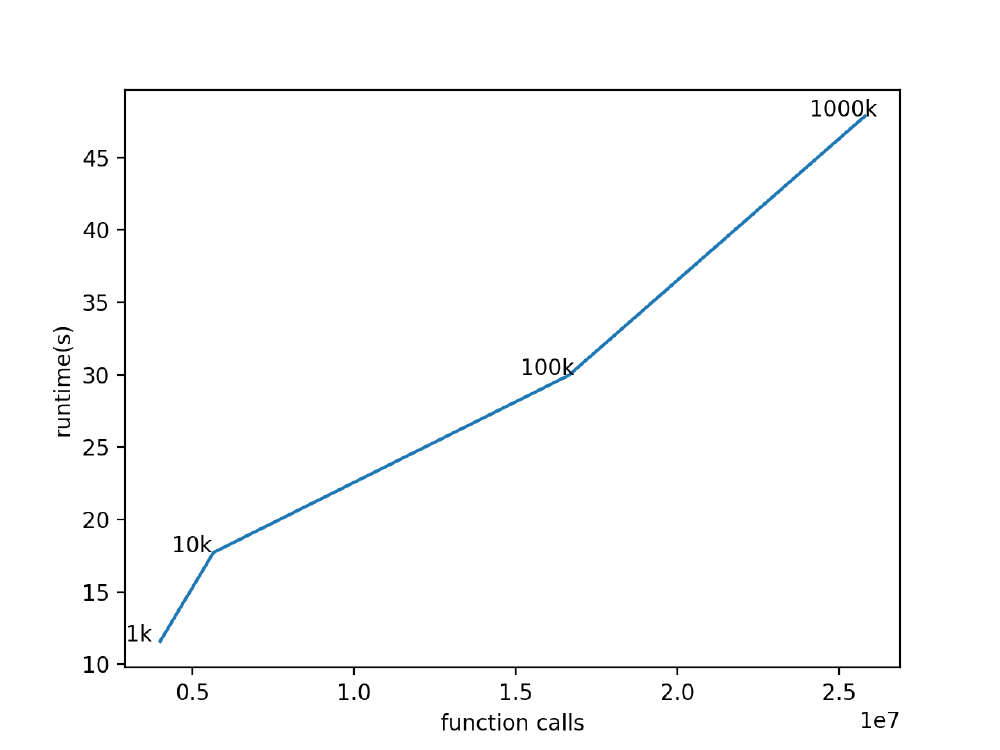
Figure: Start up time and function calls for different numbers of files.
A rise from 1k to 10k files shows an approximately 40% increase in function calls and a runtime increase of 50%. Scaling up further from 10k to 100k shows a function call increase of 200% and runtime increase of 70%. Scaling up from 100k to 1000k shows a function call increase of 288% and a runtime increase of 60%.
There is no exponential or even steep increase in runtime seen by adding an increasingly large number of files every step. The function calls that increase with the number of files and have a substantial effect on runtime are:
| FunctionCall | 10k | 100k | 1000k |
|---|---|---|---|
| base.py:284(iter_paths) | 0.378 | 2.658 | 4.488 |
| path.py:194(unexpand) | 0.366 | 2.578 | 4.313 |
| path.py:449(get_home_dir) | 0.289 | 2.050 | 3.427 |
| _stdlib.py:91(expanduser) | 0.284 | 2.012 | 3.360 |
| _stdlib.py:53(_get_userdir) | 0.219 | 1.550 | 2.587 |
Iter_paths() yields paths contained in root (symlinks dereferenced). Unexpand() replaces the user’s home directory with ~ or %USERPROFILE%, if it appears at the start of the path name. Get_home_dir() Returns the root directory of the user, /home/user or C:\Users\user. Expandeuser and get_user_dir are from the stdlib. The library contains built-in modules (written in C) that provide access to system functionality such as file I/O. In terms of scalability, file growth of a factor 10 results in a runtime increase of less than a factor 10. No exponential growth is noted here which adheres to decent scalability.
Memory Usage
Tests were done the following way
- Open Quod Libet using memory_profiler
- Navigate to the directory and import the files
- Wait until files are imported
- Once files are imported, close the application
Based on our results, we conclude that increasing the number of songs imported by a factor of 10 approximately doubles the amount of memory occupied.
1,000 Songs
1000 files were imported by Quod Libet, for a maximum RAM usage of ~130 MB.

Figure: Testing Quod Libet on 1000 files
10,000 Songs
10,000 files were imported by Quod Libet, for a maximum RAM usage of ~140 MB.
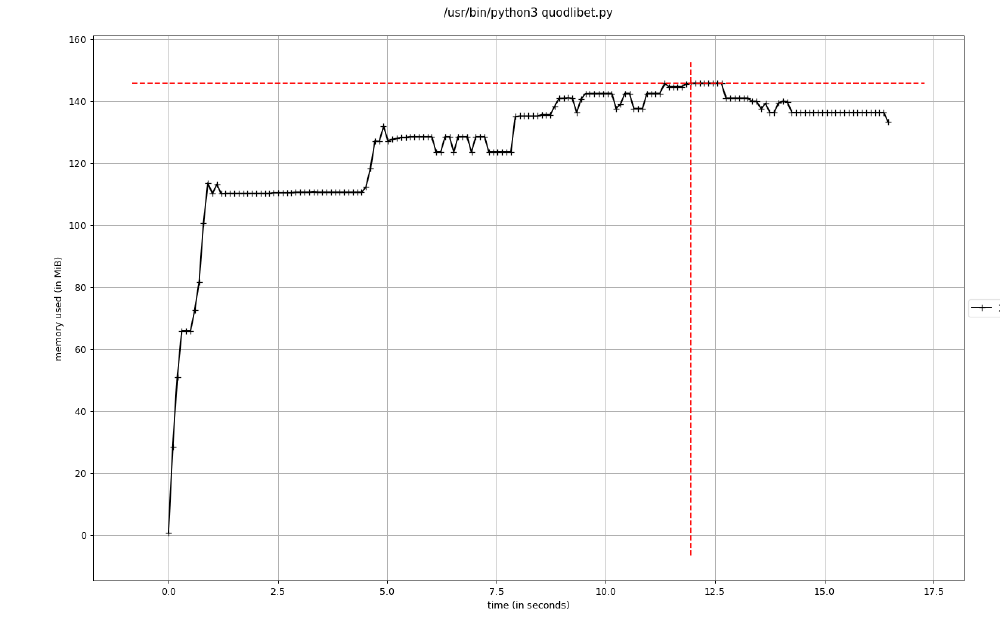
Figure: Testing Quod Libet on 10000 files
100,000 Songs
Quod Libet began to struggle with 100,000 files. Max memory usage was ~370 MB, over double previous tests. The time taken to import every file exceeded 40 seconds, more than twice as much as previous tests.
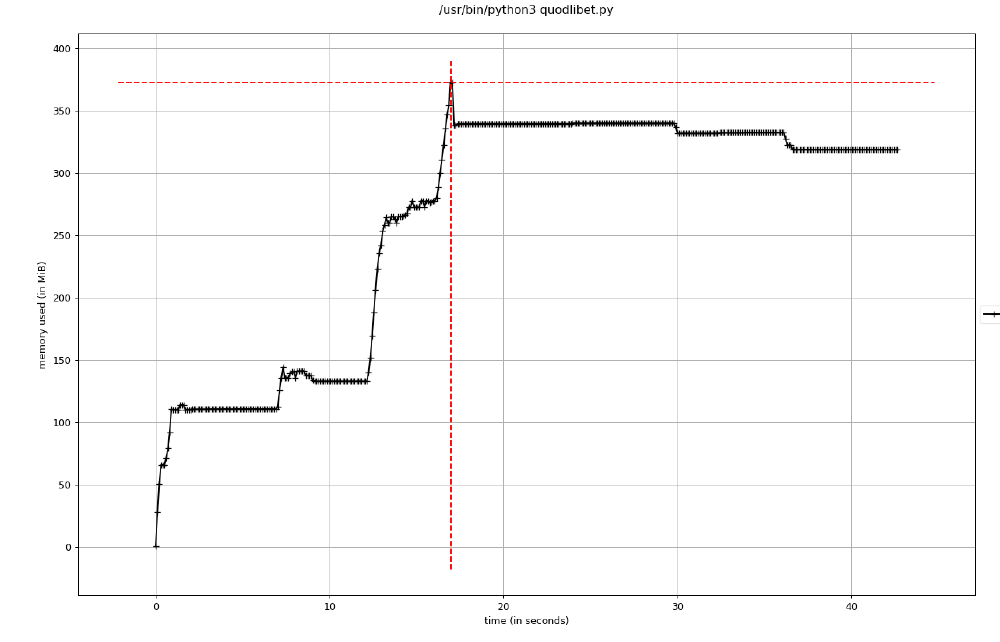
Figure: Testing Quod Libet on 100000 files
1,000,000 Songs
For 1,000,000 songs, the max memory usage was 620mb, 1.7 times the 100,000 song test, the time taken to import the data was 55 seconds.

Figure: Testing Quod Libet on 1000000 files
Architectural Decisions
Even for cases where the application takes many seconds to load the user’s files, Quod Libet manages to stay performant after this task is done. How can Quod Libet display such massive lists of songs and files, without introducing latency or stuttering? Its solution is to take advantage of a Gtk UI component designed for just this purpose: the TreeView.
Gtk’s TreeView Widget
The Gtk.TreeView widget is designed for navigating and modifying large collections of data. As its namesake suggests, it’s useful for displaying collapsible trees, like directory structures. Its functionality extends far beyond this, and in Gtk 3 it’s also the most performant way of displaying lists and tables 3.
Quod Libet uses the TreeView widget in several places key to scalability. The File Browser is naturally built around a tree view, and so is the widget showing the Song list. Other parts of Quod Libet use the tree view to show Albums, Playlists, and Artists. Any of these collections can and do get very large, so the importance of the TreeView’s performance is clear.
The Gtk TreeView is designed to have very good scaling properties, using a Model-View-Controller architecture. Most Gtk widgets don’t expose the MVC architecture to the developer, typically fusing the Model and View (for example, there is no separate LabelView and LabelContent widget). By contrast, the TreeView system is explicit about its MVC structure. The TreeView widget must be backed by data provided in the form of a Gtk TreeModel.
The naive approach to displaying lists creates a UI component or “widget” for every element in the model, but that runs into problems quickly. Widgets are resource-heavy, so creating tens of thousands of them isn’t an option.
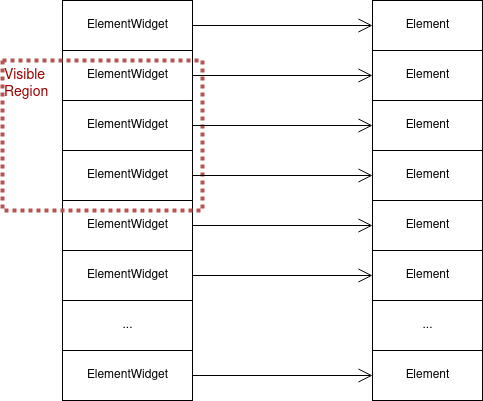
Figure: The naive approach for displaying a large list of elements involves creating a UI component for each.
Luckily, not every widget will actually be on the screen at once; we can take advantage of this to get over this performance hurdle. The most straightforward approach to this is to construct new widgets for each element as they scroll into view, destroying them as they go out of sight.

Figure: A typical solution is to create new UI components for elements that come into view as the user scrolls down.
Rather than using widgets to display each element in the Model, the TreeView uses CellRenderers to statelessly draw the visible elements to the screen. When the user scrolls, a CellRenderer only needs to change which subset of elements it gets data from, and redraw. This is faster than creating and deleting widgets whenever an element scrolls into our out of sight, and it takes up orders of magnitude less space than creating a widget for every element in the TreeModel 4.
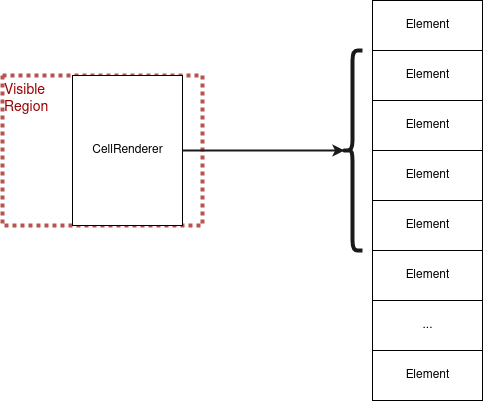
Figure: The TreeView’s approach uses a stateless CellRenderer type to draw only the visible elements.
Proposed Changes
As effective as the TreeView is for this purpose, it’s not perfect. The CellRenderer has rather limited functionality, and hasn’t received any benefit from many of the performance improvements in Gtk 4. Worse, according to the developers the TreeView struggles to scale beyond about 100,000 elements 5. To go beyond these limitations, Quod Libet could transition to the next generation of MVC-based list widgets: the ListView.
Gtk 4’s ListView Widget
The Gtk ListView widget was added in Gtk 4, and it’s designed to fill some of the same niches as the TreeView. It can display flat lists and tables, but not trees. Because it uses Widgets instead of CellRenderers, it can display its content in more flexible formats. It also has better scalability properties than the TreeView because of differences in its architecture.
Quod Libet’s file browser needs the TreeView to display a hierarchical structure, but elsewhere the TreeView is used to display Albums, Playlists, and Songs in tabular form, something the new ListView is designed for. This means that most of Quod Libet’s TreeViews can be directly replaced by ListViews.
According to the GTK developers, the TreeView class can be expected to perform well for up to 100,000 elements. Beyond this point performance may decline, in the form of increasing latencies or occasional freezing. The new ListView manages to completely remove this limitation, and the developers claim that it should perform well even for data collections of unbounded size.
A lot of the better performance of the ListView comes from differences to the way the model works. QuodLibet typically uses ListModelStore classes to hold its data, which are backed by simple list types. By contrast, ListModel is an interface for indexed access to data. The developer can implement a list-based ListModel, but it’s just as possible to implement it using an element-factory. This means that the total collection of elements never needs to fit in memory, eliminating a major limit to scalability.

Figure: The ListView’s approach is to create a fixed number of UI components on start, and re-bind them when they get reused.
Some performance advantage also comes from the way the view represents its window into the model. When the view is created, enough element widgets are created to display the elements in view. When the user scrolls, widgets that go out of sight at the top are re-bound to later elements in the model and reappear at the bottom. In this way, only a small number of widgets ever need to be created; re-binding existing widgets to different elements can be done much more cheaply than creating new widgets. Moreover, the number of widgets that need to be created depends only on the size of the user’s window, and not on the number of elements contained in the ListModel.