Key Quality Attributes
Scrapy, as explained in the previous essays, is a framework that allows for easy, fast and custom web-crawling for a variety of tasks. The main selling points of Scrapy are performance, extensibility and portability1.
In order to achieve high performance, Scrapy bases its architecture on Twisted2, a networking framework that facilitates asynchronous and event-driven programming. Twisted is built based on the Reactor pattern and facilitates a construct that waits for events and performs callback functions. This framework also provides the so-called Deferred objects3 that help manage a sequence of callback functions that are applied to the results of asynchronous method calls. Scrapy relies on the Deferreds in order to control the flow of the asynchronous code. Benchmarking a simple Scrapy spider that simply follows links achieves a performance of around 3000 pages crawled per minute4. The performance highly depends on the performance of the actual spiders that crawl the pages.
Moreover, Scrapy provides a module of extensions that allows for adding custom functionality. The extensions module provides some already implemented extensions such as the Telnet console extension (for easy debugging) and the Memory usage extension (for monitoring the memory usage of the running Scrapy process). Available extensions and instructions on adding custom extensions are discussed in Scrapy’s documentation5.
Lastly, Scrapy is a cross-platform framework, written in Python and can be run on Linux, Windows, Mac and BSD platforms. Nonetheless, some in-built extensions, discussed in the previous paragraph, do not work on all the platforms. For example, the Memory Usage extension is not functional on Windows.
The processes that ensure Scrapy’s code is high quality are as follows:
- Automated Code coverage reports
- Code style and security checks using flake8, pylint and bandit
- Mocking a deployment on all 3 major OSs
- Code Review with at least 2 Maintainers needed to approve a Pull Request
Continuous Integration Processes
In the last days of 2020 the Scrapy team started migrating some CI flows from Travis CI to Github Actions and on January 1 2021, a pull request was merged that marked the full migration to Github Actions, thus the end of Travis CI usage.
When a Pull Request is created, four pipelines run. The main one is the checks pipeline that runs tox jobs, namely bandit for security checks, flake8 for style and pylint for code analysis. Finally, it checks whether the docs are generated properly.
The other three pipelines each run the whole test suite, but each on a different OS, i.e: macOS, Windows and Ubuntu Linux. The code coverage of these is uploaded to the CodeCov GitHub app where the bot will comment the coverage on the Pull Request or Commit.
When code is committed in the main branch, the pipelines above run along with the publish pipeline, which checks the tag and pushes the code into PyPI under the new tag.
Test Processes
The documentation of Scrapy explicitly states:
“All functionality must include a test case to check that it works as expected, so please include tests for your patches if you want them to get accepted sooner” 6.
On their latest coverage report on 11/03/2022 7, the code coverage of Scrapy is 83%, which is above the 63rd percentile according to CodeCov 8.
Hotspot Components
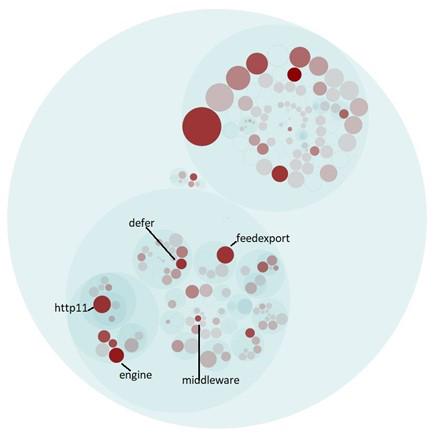
Figure: Scrapy’s Hotspot Components
Hotspots are defined as sections of code that are often modified. This frequent modification can have several different explanations, such as Unstable interface, Implicit cross-module dependency, Unhealthy interface inheritance hierarchy, Cross-module cycle and Cross-package cycle 9.
To analyze Scrapy’s hotspots, we used the tool CodeScene, as depicted in the figure above. These past hotspots were then analyzed to determine the reason a piece of code was a hotspot in Scrapy:
- Engine.py: This file contains Scrapy’s “brain” that communicates with all other components and arranges the data flow. Methods such as crawl(), init(), and download have upward of 30 changes, an increasing level of cyclomatic complexity, and a high degree of coupling, i.e. 30%. The reason that this file is a hotspot is due to the Unstable Interface problem, meaning that changes ripple through the system.
- Feedexport.py: This file also holds core functionality for Scrapy. The leading methods with a high number of changes are the init() methods of the Feed and S3FeedStorage; also the close_spider() method, with several helper methods having up to 76% coupling. The reason is the Cross-Package cycle problem, meaning it depends on other files outside of its realm of change 9.
- Defer.py: Scrapy’s documentation states that this is a helper file for the Twisted library which Scrapy is built upon. Unlike the previous files, the methods with the most changes, mustbe_deffered() and defer_suceed(), have only 8 changes. However, many of these changes were made recently, while also having significant duplicated code, suggesting this is a current and potentially upcoming hotspot. The main reason this file is a hotspot is that it depends on an outside package and deals with it internally.
- Middleware.py: Holds the interface between the Engine, Spider and Downloader. Since the functionality and implementation of this file depend on three different components. which are under constant change, it’s hotspot status is no surprise. The most changed method, from_settings(), is a recurring function in different components that seems to be susceptible to change in all of its variations. The reason behind this constant change in the Middleware.py file is the Unstable Interface since it changes as other files around it change 9. CodeScene gives an overall positive code review for this file, with a focus on the low overall code complexity.
- Http11.py: This file contains the logic for one of the handlers in the Downloader section of scrapy, meaning it concerns itself with how to access and read files. The most changed methods, init(), _cb_bodyready() and _get_agent() all have undergone many adjustments due to changes in the HTTP protocols and different internal handling. This is to be expected, and this frequent code change is due to the Cross-module cycle 9. Similarly to Feedexport.py, this file has a significant coupling degree of up to 68%, and 3 methods with a cyclomatic complexity of 10. This is a bad sign, as it can lead to bugs or testing difficulties.
The main hotspot that has been left out of the discussion is test_feedexport.py because it is a test file.
The overall code quality of Scrapy according to both CodeSource and the team’s own evaluation seems to be satisfiable when it comes to naming standards, simple methods and functionality. However, there are exceptions to this rule, and to improve the code, e.g.: lower cyclomatic complexity, or fewer arguments per method, it is recommended to refactor some methods.
Quality Culture
Ten issues and ten pull requests are analyzed to get an understanding of Scrapy’s quality culture. This analysis focuses on the communication of Scrapy members, as their communication as leaders provides an indication of the project’s quality culture10. The findings of this analysis are depicted in the tables below.
From this analysis we learn that the average response time of members is low. Besides some outliers, response is usually provided within a few days. Besides fast response time, members are also actively involved in discussions and play a supportive role, which is an indicator of a strong quality culture 11.
Other indicators of the quality culture at Scrapy are the “willingness to admit mistakes” of its members. An example of this is how a member was corrected by a contributor and responded with:
You are right, I should check my sources better :) 12
This transparency and ownership of (small) mistakes by members, combined with the informal communication style in discussions, lowers participation barriers for contributors. This helps establish a sustainable community of contributors, which is a vital success factor of an OS project 13.
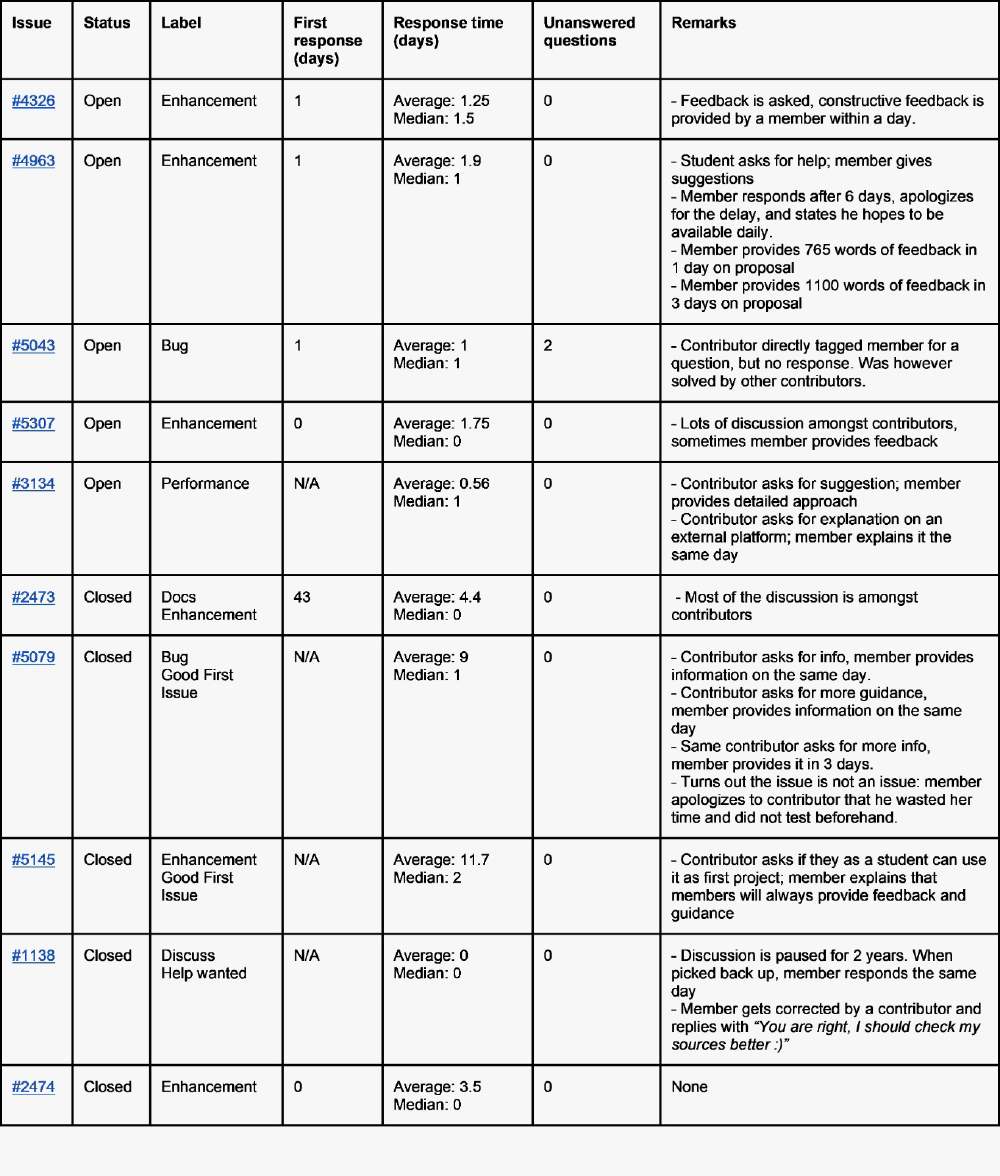
Figure: Analysis of Scrapy Github Issues

Figure: Analysis of Scrapy Github Pull Requests
Technical Debt
Technical Debt refers to making a poor design/implementation decision for the sake of fast development. It can either be regarded as an asset or as a liability. In development, a trade-off is made between development time and good design/implementation decisions. These poor design decisions can accumulate and lead to serious problems in the future, which significantly impact the system. Fixing these design decisions requires resources to “pay back” that technical debt, for example by refactoring.
We used the SonarQube’s static analysis tool to get an insight into the technical debt of the Scrapy system. Running the analysis gives an estimation of 1 day and 6 hours of technical debt, spread across bugs, vulnerabilities and code smells as follows:
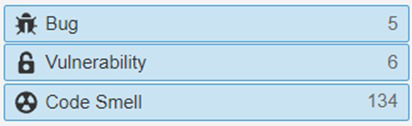
Figure: SonarQube Analysis Overview
Bugs
The current detected bugs in the system add up to 1 hour and 40 minutes of technical debt. The critical detected bugs refer to using return/break/continue in the finally block which suppresses the propagation of exceptions that were unhandled in the previous try/catch blocks and ignores the previous return statements in those blocks.

Figure: Bug Analysis
Vulnerabilities
The main security vulnerabilities detected refer to using an older version of the SSL/TLS protocol which were proven to be insecure, adding up to 20 minutes of the technical debt. However, this is not an actual vulnerability, it is just a confusing variable name. The default protocol is one of the latest TLS protocols.
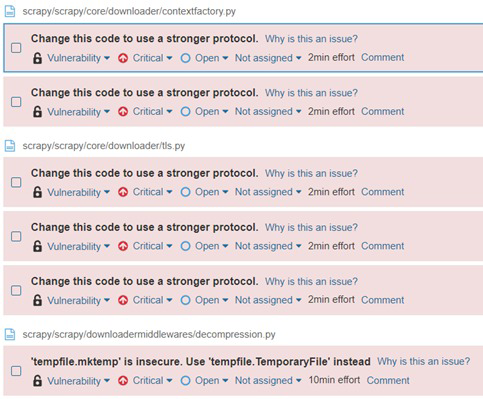
Figure: Vulnerability Analysis
Code Smells
The main source of the technical debt detected is represented by the code smells that add up to 1 day and 4 hours of estimated effort to tackle. They are 134 in total and most of them represent renaming methods or class fields to match the Python naming convention. Some of the rest of the code smells are high cognitive complexity, missing comments for empty methods, name clashes, etc.
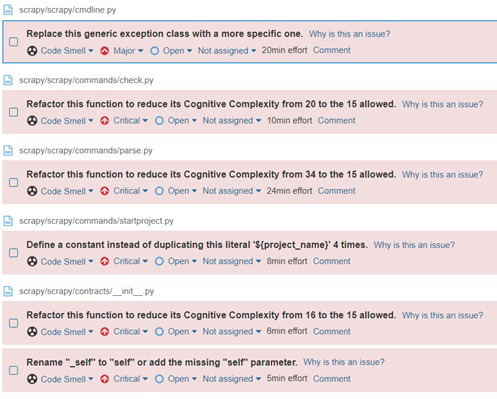
Figure: Code Smell Analysis
On top of this, Scrapy’s codebase contains some deprecated functions14. This deprecated code is a form of technical debt as it will need to be removed or replaced in the future. Additionally, a system consisting of both deprecated and non-deprecated parts requires more effort to maintain 15.
Scrapy’s deprecation policy16 ensures that support for deprecated features lasts for one year, after which new releases may remove support for deprecated features. This policy thus minimizes the risk that removal of features leads to issues with a one-year ‘phasing out’ phase. Interestingly, this deprecation policy does not discuss the removal of deprecated code, allowing for technical debt to build up. It does however seem that members monitor this deprecated code, and bring it up when it can be removed 17.
The main limitation of static analysis tools such as SonarQube is that it lacks the context of the analyzed application and cannot account for large pieces of technical debt, spread across different modules, that are present in the system.
Bibliography
-
Scrapy | A Fast and Powerful Scraping and Web Crawling Framework. (n.d.). Retrieved 18 March 2022, from https://scrapy.org/ ↩︎
-
What is Twisted? (2022, February 7). Retrieved 18 March 2022, from https://twistedmatrix.com/trac/ ↩︎
-
Deferred Reference — Twisted 16.2.0 documentation. (n.d.). Retrieved 19 March 2022, from https://twistedmatrix.com/documents/16.2.0/core/howto/defer.html ↩︎
-
Benchmarking — Scrapy 2.6.1 documentation. (2022, March 15). Retrieved 18 March 2022, from https://docs.scrapy.org/en/latest/topics/benchmarking.html ↩︎
-
Extensions — Scrapy 2.6.1 documentation. (2022, March 15). Retrieved 18 March 2022, from https://docs.scrapy.org/en/latest/topics/extensions.html#built-in-extensions-reference ↩︎
-
Contributing to Scrapy — Scrapy 2.6.1 documentation. (2022, March 17). Retrieved 17 March 2022, from https://docs.scrapy.org/en/master/contributing.html ↩︎
-
Coverage report. (n.d.). Retrieved 19 March 2022, from http://static.scrapy.org/coverage-report/ ↩︎
-
Codecov. (n.d.). 2021 State of Open Source Code Coverage. Retrieved 16 March 2022, from https://about.codecov.io/resource/2021-state-of-open-source-code-coverage/ ↩︎
-
Colyer, A. (2016, June 10). Hotspot Patterns: The formal definition and automatic detection of architecture smells | the morning paper. Retrieved 19 March 2022, from https://blog.acolyer.org/2016/06/10/hotspot-patterns-the-formal-definition-and-automatic-detection-of-architecture-smells/#:%7E:text=There%20are%20five%20architectural%20hotspot,Unhealthy%20interface%20inheritance%20hierarchy ↩︎
-
Danos, S. (n.d.). How to Create a Culture of Quality Without Sacrificing Speed. Retrieved 18 March 2022, from https://www.smartsheet.com/content-center/executive-center/leadership/how-create-culture-quality-without-sacrificing-speed ↩︎
-
ETQ. (2022, February 28). 7 Signs of a Strong Culture of Quality. Retrieved 20 March 2022, from https://www.etq.com/blog/7-signs-of-a-strong-culture-of-quality/ ↩︎
-
Alternative way to pass arguments to callback · Issue #1138 · scrapy/scrapy. (2015, April 6). Retrieved 19 March 2022, from https://github.com/scrapy/scrapy/issues/1138 ↩︎
-
Aberdour, M. (2007). Achieving quality in open-source software. IEEE software, 24(1), 58-64. ↩︎
-
Deprecations — Scrapy 1.8.0 documentation. (n.d.). Retrieved 20 March 2022, from https://scrapy-gallaecio.readthedocs.io/en/deprecation-timeline/deprecations.html ↩︎
-
Gregory, K. (2013, October 25). Deprecation and Technical Debt. Retrieved 20 March 2022, from http://blog.kdgregory.com/2013/10/deprecation-and-technical-debt.html ↩︎
-
Versioning and API stability — Scrapy 2.6.1 documentation. (2022, March 17). Retrieved 20 March 2022, from https://docs.scrapy.org/en/master/versioning.html#deprecation-policy ↩︎
-
Should we delete the deprecated code in Scrapy 2.0? · Issue #4356 · scrapy/scrapy. (2020, February 20). Retrieved 20 March 2022, from https://github.com/scrapy/scrapy/issues/4356 ↩︎