Introduction
Snakemake 1 is an open source workflow management system inspired by the GNU Make 2 build automation tool. Snakemake aims to facilitate sustainable data analysis by supporting reproducible, adaptable, and transparent data research.
In this essay we analyze the code quality and how this is tested as well as the evolution of the codebase.
This article is based on an interview we conducted with the code owner of Snakemake, Johannes Köster, as well as our own research into the repository of Snakemake. It is part of a series of four essays on the software architecture of Snakemake.
Feature creep
Snakemake has a lot of features available. The current version of the main paper associated with Snakemake 3 mentions (in no particular order): Script integration, automated unit test generation, standardized code linting and formatting, Conda integration, container integration, workflow composition, tool wrappers and Jupyter Notebook integration. This list is only a small glimpse in the full spectrum of features Snakemake has to offer.
When faced with such an overwhelming suite of features, one might wonder if this amount is excessive. Having too many features can both confuse the user, as they can have trouble finding the functionality they are looking for, as well as make development very difficult. The great number of open issues on the project’s github page (more than 500 at the time of writing) 4 exemplify this.
Feature creep is often a result of poor planning, with features being added according to users’ demands, rather than being planned out beforehand. But is that the case here?
During our interview with Köster, we mentioned this topic, and he told us that while there are many features in Snakemake, there definitely is a plan behind all of it.
Snakemake is a workflow manager, and therefore has to interact with a diverse mix of software, all used in different parts of the workflow pipeline. Interacting with such a vast array of software requires a vast array of features. To paraphrase Köster, if a user finds your workflow manager to be lacking a certain feature, the user will switch to a different workflow manager. So, there is a big push to release features fast.
However, the number of features did cause the large number of issues currently on the project’s Github page 1, over half of which are bug reports. It should be noted that the issue board is not actively moderated, so a portion of the issues might be duplicate issues. Additionally, in the past year Snakemake has undergone a phase of rapid expansion, with many new (important) features having been added in the latest release, such as modularization support and deck partitioning. The planning for the project is to undergo a stabilization phase in the upcoming year, with Köster hoping to get the number of bug reports on Github to zero by the end of the year.
The bus factor
Snakemake is a project created by Köster in 2012. Since then, many other contributors have joined the project. However, 10 years later, Köster is still the main contributor, with about 2500 commits on github vs. about 75 for the second biggest contributor.
The, perhaps morbidly named, bus factor is a measure of risk in a project resulting from a limited number of persons being knowledgeable about its working “in case they get hit by a bus” 5. The bus factor of Snakemake is one, as low as it can be. One person, Köster himself, has extensive knowledge about Snakemake, and the project would suffer if he would stop working on it (to state it less morbidly).
Currently Köster has no plans to stop working on the project, as he sees it as the main project he is known for. However, when he is old and retires, he hopes someone will take over. For the foreseeable future, however, there are no plans to train a second main developer.
Quality of testing process
Testing a project such as Snakemake comes with many difficulties as Snakemake has to connect to many outside components. Snakemake provides the feature of running on different HPC clusters and can have its files on different remote providers. If you want to test all this functionality it would be good to mock these services to mimic their behavior and have that tested. As well as testing specific components in a controlled environment.
It seems Snakemake’s test suite cannot easily be run in such a controlled environment and needs some work. We tried to run the tests on our local machine following the guidelines on the documentation for testing. 6 The documentation suggests running nosetests, but as it seems there are also a lot of pytest imports in the codebase. We ran both. Nosetest ran 284 tests in 2261 seconds with 20 errors and 37 failures. Pytest ran 53 tests, but 8 skipped, in 40 seconds with 2 failed, 1 warning. There are many missing module errors, despite activating the conda environment specified for testing, but also some missing credentials errors. Searching the codebase also resulted in very little use of mock classes and most tests simply run a Snakemake highlighting an issue instead of a specific unittest for that component. With being unclear what testing framework is used and with many configuration errors the quality of test suite needs some work.
A good way to keep test quality in control is to see if all code is ran when running the test suite. This measure is called the test coverage. The Snakemake codebase does not measure its test coverage and we doubt to what extent it is possible with the way Snakemake is designed and how the test suite is designed. Most of the tests simply spawn a separate Snakemake process and aren’t making an API call. Secondly a large part of the code is ran via the exec call with the parser. We don’t think that test coverage framework are able to analyze the covered lines of code with how they are executed. The information of what lines are executed is lost with all these separate layers of execution.
Analysis of hotspots
In thr figure below you can see a hotspot analysis of the codebase. We looked at the file size, indicating a component’s complexity, and mapped it against the number of commits to that file. As can be seen the files complexity scales equally with the number of times a file has been refactored. The main __init__.py , the workflow.py, and the [dag.py] file have seen the most commits. It is probably a good idea to break these files up in smaller components to keep the amount of refactoring in certain parts of the code small. The components that seemed to be better designed are the components for deployment and executing, such as the executors/__init__.py, [conda.py] and google_lifesciences.py. They are relatively large files, but have not seen as many commits. An interesting smaller file would be the [gridftp.py] file as it has been refactored much more often than expected from its size, indicating there are or have been some problems with its design.

Figure 1: A plot highlighting what files are the most refactored
Continuous Integration
The continuous integration (CI) of Snakemake is done in Github. It uses the action system provided by Github 7. At the time of writing four workflows are used on the repository 8, of which one ‘main.yml’ is used for continuous integration. In addition to the main workflow file, the Sonarcloud Github plugin is used to analyze software quality 9. This plugin comments on merge requests with its analysis on: security, maintainability, reliability, code coverage, and code duplications. We noticed that Snakemake uses the free version of Google Cloud. Because of this, Google Cloud had to be disabled in the CI this month, since the free credits had run out. If this becomes a frequent issue it can pose a problem for quality control.
Let’s now take a look at the content of the CI. The first action taken is to cancel any previous still running workflow, sparing resources. The second step is to check the formatting of the code and tests. This is done by using the code formatter Black 10. The third action, setting up the environment, is done for both Windows and Ubuntu. This is done so that tests can be run for both Ubuntu and Windows. We would like to mention that the tests for Windows are significantly more limited in comparison to Ubuntu though. On Ubuntu the following tests are run in the CI:
pytest -v -x tests/test_expand.py tests/test_io.py tests/test_schema.py tests/test_linting.py tests/tests.py
Compared to Windows, which only runs one of these test suites:
python -m pytest -v -x tests/tests.py
The environment of Ubuntu consists of the following steps:
-
mamba create snakemake
-
mamba install singularity 11
-
apt install git, stress, wget
-
Setup iRods 12
-
Setup Gcloud 13
-
Setup AWS 14
For Windows only MiniConda is installed, so that the Snakemake environment can be set up via mamba.
After setting up the environment the before-mentioned test files are run. The next action consists of building and pushing the docker image 15, followed by testing external tools on Ubuntu: Kubernetes16, AWS, Google Life Sciences and GA4GH TES.
The CI seems to be extensive and covers what would be expected. The only issue may be its limited testing on Windows and the use of the free version of Google Cloud.
Quality Culture
To assess the quality culture of the Snakemake project, we analyzed 10 major issue discussion from the GitHub repository and their corresponding merge requests (if applicable). To see a complete (informal) overview of the analyzed discussions, please refer to the appendix. Here, we will summarize our findings.
One very strong pattern we found is that Köster acts as a guardian against violations of Snakemake’s core design principles. In multiple occasions, he stops contributors pursuing a certain solution, e.g. explaining how this breaks transparency and reproducibility 17, or portability 18. Furthermore, Köster prevents contributors from writing new features that can already be accomplished through existing features [^gc-5]. In general, we think it is great that the founder of the project is still so involved as he, like no other, knows what design principles make Snakemake a great workflow management tool. It does however pose a risk, as described in “The Bus Factor” section.
As Köster mentioned, he aims for Snakemake to support new popular remote file services or executor platforms as fast as possible, as this guarantees that Snakemake remains useful to researchers. In line with this objective, Köster regularly opens a special issue when support for a new remote file service or executor is added. In this issue, he encourages users and contributors to come up with feature requests resulting from the newly supported remote file service or executor platform. Examples of such issues are 19, 18 and 20. The discussions are interesting and indeed result in new contributions, but we also see that the discussions can get chaotic as some users ask questions about the original new feature instead of suggesting new follow-up features. Therefore, we think some discussion moderation might be in order here, as is splitting up the questions from the feature requests.
Fortunately, Köster is not the only developer with a deep understanding of the design principles and codebase of Snakemake. As evidenced by 21, 22, 23 and 20. In some of these discussions no input from Johannes was required, and in others, the fruitful discussion lead to new entirely new ideas or even major releases by Johannes. This exemplified by 17 and 24.
Lastly, we found it interesting to note that a formatter for Snakemake was requested and subsequently developed from the ground up by people other than Köster, in a separate repository 25. Köster promised co-authorship for the newest Snakemake paper for those who would develop the new formatter 26. It turned out to be a surprisingly effective motivator for people to develop this feature.
Analysis of issue history
As Köster often has to prioritize the development of new features over solving bugs (to keep up with new backend services), we wondered if we would see a spike in opened bug issues right after new major releases. To this end, we used a web scraper to gather all issues, their tags and date of creation. This is shown in Figure 2 (the current repository history only goes as far back as 2019). We did not see a pattern in the rate of bug issues being opened. However, the figure does show that bug issues make up a considerable portion of the total number of issues, which could be explained by the feature focused development of Snakemake, where bug fixing often has to take a backseat.
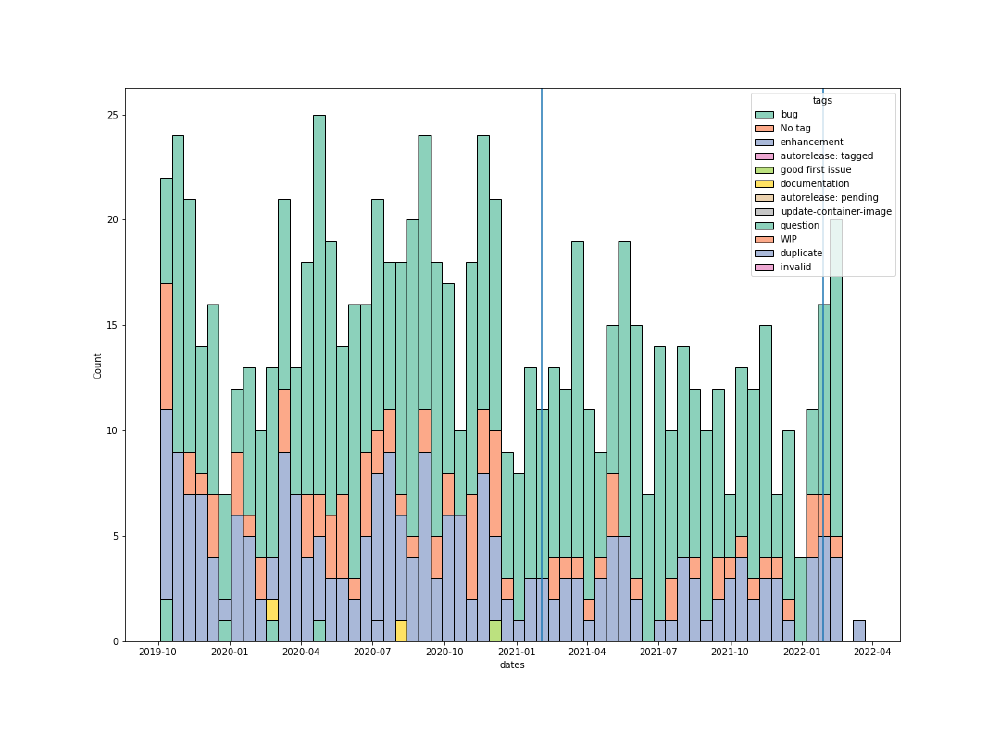
Figure 2. The issue history of the current GitHub repository of Snakemake. The blue vertical lines indicate the major release dates.
References
Appendix: Quality Culture analysis
https://github.com/snakemake/snakemake/issues/457
1) Feature requests for the google life sciences backend
- Johannes added google life sciences as a backend, and then:
- Actively asking for feature requests from the community
- Feature request merits are discussed, main contributors (johannes and vsoch) respectfully decline (in their eyes) not so good ideas and encourage people to make PRs for the good ideas!
- script on page one (good idea)
- using FUSE (bad idea)
- Discussion a bit cluttered because people also ask questions
https://github.com/snakemake/snakemake/issues/352
2) Allow conda environment activation by name on a per-rule basis
- People advocating: “I feel like the decoupling of snakemake and the environment building would result in a net positive in terms of flexibility.” - sstadick
- Johannes indicates that this would erode the core principles behind snakemake: transparency and reproducibility:
“
- I agree, conda is slow, but as we have mamba support now, speed is not an issue anymore. Mamba is lightning fast, even for complex conda environments.
- An env name is in general not suitable to ensure the same environments for different projects/workflow instances. While this might work (for a while) on a local machine, it won’t be reproducible for other machines or even lab mates. To really ensure reproducible environments, you need to define the versions properly in the environment file. Moreover you loose transparency, because people you need to be on the machine (at a certain point in time), in order to see what software stack is used for a rule.
Of course, one could nevertheless add this feature. I am open to consider a PR, if it includes a linter warning that the feature should be complemented by a normal conda directive, such that at least a bit of reproducibility is maintained if others want to run the workflow.
”
- But he is open to consider a PR for the feature if it includes a warning that these principles are being violated.
- Users keep their stance: we really need this because! …
- Finally Johannes in convinced.
- Then someone makes a start for adding the feature: https://github.com/snakemake/snakemake/pull/494
- But Johannes thinks it could be done better / cleaner and does so in:https://github.com/snakemake/snakemake/pull/1340
https://github.com/snakemake/snakemake/issues/36
3) A formatter such as black
- Promise of co-authorship on a paper used as motivation to contribute
- Formatter made in separate repository
https://github.com/snakemake/snakemake/issues/743
4) subworkflow order enforcing
- User has problem and suggests a solution
- But other user points out this would duplicate code and be inelegant / ignore existing systems
- This user proposers a better solution
- Johannes chimes in and says he likes this last idea and is welcome to PRs
- Users start working on it here:https://github.com/snakemake/snakemake/pull/791
- This gives Johannes some valuable insights which leads to, eventually, the new modules system for snakemake: https://github.com/snakemake/snakemake/pull/888
https://github.com/snakemake/snakemake/issues/615
5) Follow input list order
- User proposes preserving the ordering of input
- People come up with a solution
- But Johannes shoots it down, as ordering is already supported through other means more explicitly
https://github.com/snakemake/snakemake/issues/592
6) Preemption for tibanna and azure
- Johannes introduces a new feature and asks other contributors to add support for this feature in various executors.
- Discussions erupt over what is the right approach, most of the discussion is in a PR for another executor: https://github.com/snakemake/snakemake/pull/549
- Summary: contributors were discussing a promising approach, but Johannes chimes in once again to point out that this would conflict with one of Snakemake’s main design principles: portability. Namely, the proposed approach was not platform independent.
- Johannes and others work out a different solution and everyone is happy.
7) New CLI argument to disable config argument type inferencing
- Feature request for a better way to enter complex arguments through the CLI
- Contributors discuss possible solutions
- This helps Johannes find the most elegant solution: using the YAML parser to interpret complex values
8) Checkpoints slow in large workflows
- There are performance issues in the creation of the DAG of jobs when lots of input samples are used in combination with the checkpoint feature
- In some way the computational cost seems unavoidable (by design)
- But the implementation could be improved
- This is still an open discussion, and Johannes has not participated in the discussion (yet)
https://github.com/snakemake/snakemake/issues/23
9) Special treatment of rule all
- A discussion about the benefits of giving special meaning to the “rule all” pattern.
- However, it is pointed out that there are numerous other ways of accomplishing what the opening post author wanted
- Furthermore, someone points out that Snakemake mirrors GNU Make and doing the proposed change would break this mirroring.
- Interestingly, Johannes is not involved in this discussion.
https://github.com/snakemake/snakemake/issues/57
10) Default remote provider for Azure Storage
- We see that Snakemake supports some new remote file system, namely Azure Storage, and again existing features are requested to also work for this new remote file.
- Discussions on implementation are in the corresponding PR: https://github.com/snakemake/snakemake/pull/324
- Seems like this is a common pattern for the remote files and executors. Often people other than Johannes help getting these running or up to date. The Pull Requests do not yield big discussions as the procedure to add support is quite the same among all executors / remote files types.
-
F. Mölder et al., “Sustainable data analysis with Snakemake” F1000Research, vol. 10. F1000 Research Ltd, p. 33, Apr. 19, 2021. doi: 10.12688/f1000research.29032.2. ↩︎
-
https://snakemake.readthedocs.io/en/stable/project_info/contributing.html#testing-guidelines ↩︎
-
https://github.com/snakemake/snakemake/tree/main/.github/workflows ↩︎
-
https://github.com/marketplace/sonarcloud/plan/MLP_kgDNGsA#pricing-and-setup ↩︎