Introduction
Snakemake 1 is an open source workflow management system inspired by the GNU Make 2 build automation tool. Snakemake aims to facilitate sustainable data analysis by supporting reproducible, adaptable, and transparent data research.
In this essay we analyze scalability challenges for Snakemake and propose a solution for the identified issues. We opted for a different approach than the original assignment, analyzing the scalability of the userbase and development of Snakemake instead of technical scalability. The reason for this is that Snakemake runs locally, it has no backend that must support an increasing number of users or load and thus has minimal technical scalability issues. The bottleneck for Snakemake are the jobs defined by the users, since that determines the load for the machine or cluster. In other words, during the execution of a Snakemake workflow, the execution time of Smakemake itself is very low compared the jobs it executes. So instead of scalability in the technical sense, we have analyzed the scalability of Snakemake’s userbase. This comes back to a point we addressed in our first essay 3, that Snakemake has the potential to be adopted in many more domains than just bioinformatics. Additionally we also propose architectural changes to improve accessibility for developers contributing to Snakemake.
This article is based on interviews we conducted with the code owner of Snakemake, Johannes Köster, as well as our own research into the repository of Snakemake. It is part of a series of four essays on the software architecture of Snakemake. Although this essay occasionally refers to the previous essays in the series, it has been written to be independently readable.
Scalability challenge
In our previous essay we mentioned that Snakemake is developed mostly by one developer, who is also the code owner of Snakemake, Johannes Köster 4. Most of the code in the repository has been developed by Köster, and in addition all pull requests have to be approved by him before they are merged. Main features contributed by others are support for remote storage providers 5 and executor platforms 6, since these are reasonably similar for each system and mostly independent from Snakemake.
The main challenge arising from this developmental process is the effect it has on scalability in regards to the userbase. At the time of writing Snakemake is mostly used by researchers in the bioinformatics domain, even though it could also be appropriately applied to other domains such as machine learning (see figure 1). It may become infeasible to support additional domains when all pull requests have to be approved by one person.
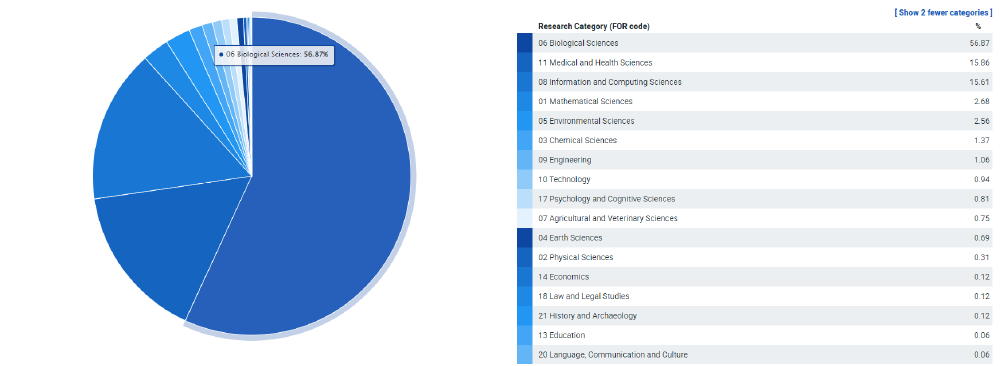
Figure: 1: Categorization of papers citing the main Snakemake paper. Source: https://badge.dimensions.ai/details/id/pub.1018944052/categories
How architecture affects scaling up
Scaling up Snakemake’s userbase to new domains is a matter of horizontal scaling, as there is no need to change Snakemake’s core functionality of providing a great workflow management system. Instead, Snakemake would benefit from additional domain-specific features that make it more appealing to non-bioinformatics data scientists. For example, the developer(s) could identify executor platforms and remote file systems that are widely used in those other domains, and integrate them into Snakemake. One promising candidate for this is AWS Batch 7.
As we mentioned in the previous section the majority of the development is currently being done by Köster. Since he has only so many hours of development time to spend on the project, horizontal scaling of Snakemake requires other developers to start seriously contributing. However, there are some architectural obstacles that should be addressed before this is feasible.
While highly modular, all of Snakemake’s code is in one single repository. There is no way for independent developers to create add-ons for Snakemake to extend its functionality, without needing revision and agreement by Köster. Therefore, we think it would be wise to move to a plugin-based system for executors and remote file systems. This way, responsibility for the development of new features can be more easily separated.
Another easily overlooked benefit of working with plugins and separate repositories, is that plugin developers actually get the credit for their work. Currently, in the eyes of the public, all contributions are effectively attributed to Johannes Köster, as he is known as the founder and main developer of Snakemake. Furthermore, Köster has published scientific papers about Snakemake, further associating his name with the project. With plugins, others could develop features specifically useful to their domain, get the credit for their work, and possibly present their work at conferences that Snakemake’s current main developer does not usually go to.
The solution: a plugin system
As mentioned above, we propose to introduce a plugin system. Below follows an in-depth explanation of how we decided to implement the plugin system. The system was developed after meeting with Köster and based on his input.
Currently, (as can be seen in figure 2), Snakemake simply modularizes the different interfaces, which derive from abstract classes for RemoteProvider and and RemoteObject. These can then be instantiated by the users. The remote module also contains an AutoRemoteProvider class that connects to all the remotes based on the protocol from the name.
For the plugin system as described in figure 3 loading we utilize the flexibility of the Python import system by using the importlib and pkgutil modules to find the plugin distributions and load. These modules are then loaded and set onto the globals() variable so that everybody importing from snakemake.remote can find them. This functionality has been put into snakemake/common/plugin.py so that other components that need a plugin infrastructure can utilize that as well.
All abstract base class are moved to snakemake/remote/common.py to prevent any circular dependencies for the plugins and using the ABC system from python we can ensure that these classes implement all the needed methods. There is still some better design and refactoring needed for these.
A plugin should be distributed as a pip package starting with the prefix snakemake-plugin-remote-. The name of the installed module will be used to set on the snakemake.remote namespace. If you want to set a name that might conflict with other globally installed modules you can set snakemake_submodule_name on your module. Your module should expose a bunch of variables such as __version__ and __author__. The RemoteProvider and RemoteObject it exposes should be derived from one of the abstract classes now moved to snakemake/remote/common.py.
The AUTO loader will now also search for the plugins next to searching for the submodules for any RemoteProviders. Some of its functionality has been broken into parts and moved to the plugin.py package as it also utilizes some of the importlib and pkgutil standard library.

Figure 2: The current implementation (”As is” architecture). Repositories shaded in blue.

Figure 3: The plugin system (”To be” architecture). Repositories shaded in blue.
Addressing scalability
We think the aforementioned plugin system will help to scale Snakemake in several ways. It should help to get more developers involved in its development and it should help Snakemake integrate more easily with other systems.
Due to the modular nature of plugins, developers require less involvement with the main Snakemake codebase in order to start coding. This should make developers more inclined to start working on extending Snakemake.
The other axis on which the plugin system will make Snakemake scale is in the number of domains it can support. Our hypothesis is as follows. As it becomes easier to write code to add domain-specific features to Snakemake, more people will do so, and therefore more domains will be supported by Snakemake.
Only the future can tell whether our hypothesis proves to be true, however it can be easily measured by looking at the number of (independently) developed plugins on the Snakemake codebase once our plugin system goes live. The number of supported domains can also be measured.
Conclusion
The future of Snakemake’s adoption into other domains will be determined by its scalability in terms of development of new domain-specific features. In this essay we have analyzed which aspect limits the scalability of Snakemake most significantly, and proposed a solution to counter this issue. The limiting aspect of Snakemake is that it has only one code owner. This leads to issues for scalability due to limited creditability for contributors and dependency on Köster for agreement to contributions. Our proposed solution for both of these issues is a plugin system, which replaces the current mono-repo structure. Plugins can be implemented independently from the main repository, which helps with the aforementioned issues. Furthermore, it can help further the adoption of Snakemake in other domains than bioinformatics. Whether this holds true can be tested in the future by measuring 1) the number of supported domains and 2) the number of independently developed plugins.
References
-
https://desosa2022.netlify.app/projects/snakemake/posts/snakemake-a-hidden-gem-for-sustainable-data-science-from-the-field-of-bioinformatics/ ↩︎
-
https://desosa2022.netlify.app/projects/snakemake/posts/snakemake-gleaming/ ↩︎
-
https://snakemake.readthedocs.io/en/stable/snakefiles/remote_files.html ↩︎
-
https://snakemake.readthedocs.io/en/stable/executing/cloud.html ↩︎